The absolute trainer to light up AI agents.

Agent Lightning⚡
![]()
![]()
![]()
![]()
The absolute trainer to light up AI agents.
Join our Discord community to connect with other users and contributors.
⚡ Core Features
- Turn your agent into an optimizable beast with ZERO CODE CHANGE (almost)! 💤
- Build with ANY agent framework (LangChain, OpenAI Agent SDK, AutoGen, CrewAI, Microsoft Agent Framework...); or even WITHOUT agent framework (Python OpenAI). You name it! 🤖
- Selectively optimize one or more agents in a multi-agent system. 🎯
- Embraces Algorithms like Reinforcement Learning, Automatic Prompt Optimization, Supervised Fine-tuning and more. 🤗
Read more on our documentation website.

⚡ Installation
pip install agentlightning
For the latest nightly build (cutting-edge features), you can install from Test PyPI:
pip install --upgrade --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple/ --pre agentlightning
Please refer to our installation guide for more details.
To start using Agent-lightning, check out our documentation and examples.
⚡ Articles
- 12/17/2025 Adopting the Trajectory Level Aggregation for Faster Training Agent-lightning blog.
- 11/4/2025 Tuning ANY AI agent with Tinker ✕ Agent-lightning Medium. See also Part 2.
- 10/22/2025 No More Retokenization Drift: Returning Token IDs via the OpenAI Compatible API Matters in Agent RL vLLM blog. See also Zhihu writeup.
- 8/11/2025 Training AI Agents to Write and Self-correct SQL with Reinforcement Learning Medium.
- 8/5/2025 Agent Lightning: Train ANY AI Agents with Reinforcement Learning arXiv paper.
- 7/26/2025 We discovered an approach to train any AI agent with RL, with (almost) zero code changes. Reddit.
- 6/6/2025 Agent Lightning - Microsoft Research Project page.
⚡ Community Projects
- DeepWerewolf — A case study of agent RL training for the Chinese Werewolf game built with AgentScope and Agent Lightning.
- AgentFlow — A modular multi-agent framework that combines planner, executor, verifier, and generator agents with the Flow-GRPO algorithm to tackle long-horizon, sparse-reward tasks.
- Youtu-Agent — Youtu-Agent lets you build and train your agent with ease. Built with a modified branch of Agent Lightning, Youtu-Agent has verified up to 128 GPUs RL training on maths/code and search capabilities with steady convergence. Also check the recipe and their blog Stop Wrestling with Your Agent RL: How Youtu-Agent Achieved Stable, 128-GPU Scaling Without Breaking a Sweat.
⚡ Architecture
Agent Lightning keeps the moving parts to a minimum so you can focus on your idea, not the plumbing. Your agent continues to run as usual; you can still use any agent framework you like; you drop in the lightweight agl.emit_xxx() helper, or let the tracer collect every prompt, tool call, and reward. Those events become structured spans that flow into the LightningStore, a central hub that keeps tasks, resources, and traces in sync.
On the other side of the store sits the algorithm you choose, or write yourself. The algorithm reads spans, learns from them, and posts updated resources such as refined prompt templates or new policy weights. The Trainer ties it all together: it streams datasets to runners, ferries resources between the store and the algorithm, and updates the inference engine when improvements land. You can either stop there, or simply let the same loop keep turning.
No rewrites, no lock-in, just a clear path from first rollout to steady improvement.

⚡ CI Status
| Workflow | Status |
|---|---|
| CPU Tests | |
| Full Tests | |
| UI Tests | |
| Examples Integration | |
| Latest Dependency Compatibility | |
| Legacy Examples Compatibility |
⚡ Citation
If you find Agent Lightning useful in your research or projects, please cite our paper:
@misc{luo2025agentlightningtrainai,
title={Agent Lightning: Train ANY AI Agents with Reinforcement Learning},
author={Xufang Luo and Yuge Zhang and Zhiyuan He and Zilong Wang and Siyun Zhao and Dongsheng Li and Luna K. Qiu and Yuqing Yang},
year={2025},
eprint={2508.03680},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.03680},
}
⚡ Contributing
This project welcomes contributions and suggestions. Start by reading the Contributing Guide for recommended contribution points, environment setup, branching conventions, and pull request expectations. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
⚡ Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
⚡ Responsible AI
This project has been evaluated and certified to comply with the Microsoft Responsible AI Standard. The team will continue to monitor and maintain the repository, addressing any severe issues, including potential harms, if they arise.
⚡ License
This project is licensed under the MIT License. See the LICENSE file for details.
A complete computer science study plan to become a software engineer.
Coding Interview University
I originally created this as a short to-do list of study topics for becoming a software engineer,
but it grew to the large list you see today. After going through this study plan, I got hired
as a Software Development Engineer at Amazon!
You probably won't have to study as much as I did. Anyway, everything you need is here.I studied about 8-12 hours a day, for several months. This is my story: Why I studied full-time for 8 months for a Google interview
Please Note: You won't need to study as much as I did. I wasted a lot of time on things I didn't need to know. More info about that is below. I'll help you get there without wasting your precious time.
The items listed here will prepare you well for a technical interview at just about any software company,
including the giants: Amazon, Facebook, Google, and Microsoft.Best of luck to you!
Translations:
Translations in progress:
What is it?

This is my multi-month study plan for becoming a software engineer for a large company.
Required:
- A little experience with coding (variables, loops, methods/functions, etc)
- Patience
- Time
Note this is a study plan for software engineering, not frontend engineering or full-stack development. There are really
super roadmaps and coursework for those career paths elsewhere (see https://roadmap.sh/ for more info).
There is a lot to learn in a university Computer Science program, but only knowing about 75% is good enough for an interview, so that's what I cover here.
For a complete CS self-taught program, the resources for my study plan have been included in Kamran Ahmed's Computer Science Roadmap: https://roadmap.sh/computer-science
Table of Contents
The Study Plan
- What is it?
- Why use it?
- How to use it
- Don't feel you aren't smart enough
- A Note About Video Resources
- Choose a Programming Language
- Books for Data Structures and Algorithms
- Interview Prep Books
- Don't Make My Mistakes
- What you Won't See Covered
- The Daily Plan
- Coding Question Practice
- Coding Problems
Topics of Study
- Algorithmic complexity / Big-O / Asymptotic analysis
- Data Structures
- More Knowledge
- Trees
- Trees - Intro
- Binary search trees: BSTs
- Heap / Priority Queue / Binary Heap
- balanced search trees (general concept, not details)
- traversals: preorder, inorder, postorder, BFS, DFS
- Sorting
- selection
- insertion
- heapsort
- quicksort
- mergesort
- Graphs
- directed
- undirected
- adjacency matrix
- adjacency list
- traversals: BFS, DFS
- Even More Knowledge
- Final Review
Getting the Job
- Update Your Resume
- Find a Job
- Interview Process & General Interview Prep
- Be thinking of for when the interview comes
- Have questions for the interviewer
- Once You've Got The Job
---------------- Everything below this point is optional ----------------
Optional Extra Topics & Resources
- Additional Books
- System Design, Scalability, Data Handling (if you have 4+ years experience)
- Additional Learning
- Compilers
- Emacs and vi(m)
- Unix command line tools
- Information theory
- Parity & Hamming Code
- Entropy
- Cryptography
- Compression
- Computer Security
- Garbage collection
- Parallel Programming
- Messaging, Serialization, and Queueing Systems
- A*
- Fast Fourier Transform
- Bloom Filter
- HyperLogLog
- Locality-Sensitive Hashing
- van Emde Boas Trees
- Augmented Data Structures
- Balanced search trees
- AVL trees
- Splay trees
- Red/black trees
- 2-3 search trees
- 2-3-4 Trees (aka 2-4 trees)
- N-ary (K-ary, M-ary) trees
- B-Trees
- k-D Trees
- Skip lists
- Network Flows
- Disjoint Sets & Union Find
- Math for Fast Processing
- Treap
- Linear Programming
- Geometry, Convex hull
- Discrete math
- Additional Detail on Some Subjects
- Video Series
- Computer Science Courses
- Papers
Why use it?
If you want to work as a software engineer for a large company, these are the things you have to know.
If you missed out on getting a degree in computer science, like I did, this will catch you up and save four years of your life.
When I started this project, I didn't know a stack from a heap, didn't know Big-O anything, or anything about trees, or how to
traverse a graph. If I had to code a sorting algorithm, I can tell ya it would have been terrible.
Every data structure I had ever used was built into the language, and I didn't know how they worked
under the hood at all. I never had to manage memory unless a process I was running would give an "out of
memory" error, and then I'd have to find a workaround. I used a few multidimensional arrays in my life and
thousands of associative arrays, but I never created data structures from scratch.
It's a long plan. It may take you months. If you are familiar with a lot of this already it will take you a lot less time.
How to use it
Everything below is an outline, and you should tackle the items in order from top to bottom.
I'm using GitHub's special markdown flavor, including tasks lists to track progress.
If you don't want to use git
On this page, click the Code button near the top, then click "Download ZIP". Unzip the file and you can work with the text files.
If you're open in a code editor that understands markdown, you'll see everything formatted nicely.

If you're comfortable with git
Create a new branch so you can check items like this, just put an x in the brackets: [x]
-
Fork the GitHub repo:
https://github.com/jwasham/coding-interview-universityby clicking on the Fork button.
-
Clone to your local repo:
git clone https://github.com/<YOUR_GITHUB_USERNAME>/coding-interview-university.git cd coding-interview-university git remote add upstream https://github.com/jwasham/coding-interview-university.git git remote set-url --push upstream DISABLE # so that you don't push your personal progress back to the original repo -
Mark all boxes with X after you completed your changes:
git commit -am "Marked personal progress" git pull upstream main # keep your fork up-to-date with changes from the original repo git push # just pushes to your fork
Don't feel you aren't smart enough
- Successful software engineers are smart, but many have an insecurity that they aren't smart enough.
- The following videos may help you overcome this insecurity:
A Note About Video Resources
Some videos are available only by enrolling in a Coursera or EdX class. These are called MOOCs.
Sometimes the classes are not in session so you have to wait a couple of months, so you have no access.
It would be great to replace the online course resources with free and always-available public sources,
such as YouTube videos (preferably university lectures), so that you people can study these anytime,
not just when a specific online course is in session.
Choose a Programming Language
You'll need to choose a programming language for the coding interviews you do,
but you'll also need to find a language that you can use to study computer science concepts.
Preferably the language would be the same, so that you only need to be proficient in one.
For this Study Plan
When I did the study plan, I used 2 languages for most of it: C and Python
- C: Very low level. Allows you to deal with pointers and memory allocation/deallocation, so you feel the data structures
and algorithms in your bones. In higher-level languages like Python or Java, these are hidden from you. In day-to-day work, that's terrific,
but when you're learning how these low-level data structures are built, it's great to feel close to the metal.- C is everywhere. You'll see examples in books, lectures, videos, everywhere while you're studying.
- The C Programming Language, 2nd Edition
- This is a short book, but it will give you a great handle on the C language and if you practice it a little
you'll quickly get proficient. Understanding C helps you understand how programs and memory work. - You don't need to go super deep in the book (or even finish it). Just get to where you're comfortable reading and writing in C.
- This is a short book, but it will give you a great handle on the C language and if you practice it a little
- Python: Modern and very expressive, I learned it because it's just super useful and also allows me to write less code in an interview.
This is my preference. You do what you like, of course.
You may not need it, but here are some sites for learning a new language:
For your Coding Interview
You can use a language you are comfortable in to do the coding part of the interview, but for large companies, these are solid choices:
- C++
- Java
- Python
You could also use these, but read around first. There may be caveats:
- JavaScript
- Ruby
Here is an article I wrote about choosing a language for the interview:
Pick One Language for the Coding Interview.
This is the original article my post was based on: Choosing a Programming Language for Interviews
You need to be very comfortable in the language and be knowledgeable.
Read more about choices:
See language-specific resources here
Books for Data Structures and Algorithms
This book will form your foundation for computer science.
Just choose one, in a language that you will be comfortable with. You'll be doing a lot of reading and coding.
Python
- Coding Interview Patterns: Nail Your Next Coding Interview (Main Recommendation)
- An insider’s perspective on what interviewers are truly looking for and why.
- 101 real coding interview problems with detailed solutions.
- Intuitive explanations that guide you through each problem as if you were solving it in a live interview.
- 1000+ diagrams to illustrate key concepts and patterns.
C
- Algorithms in C, Parts 1-5 (Bundle), 3rd Edition
- Fundamentals, Data Structures, Sorting, Searching, and Graph Algorithms
Java
Your choice:
- Goodrich, Tamassia, Goldwasser
- Sedgewick and Wayne:
- Algorithms
- Free Coursera course that covers the book (taught by the authors!):
C++
Your choice:
- Goodrich, Tamassia, and Mount
- Sedgewick and Wayne
Interview Prep Books
Here are some recommended books to supplement your learning.
-
Programming Interviews Exposed: Coding Your Way Through the Interview, 4th Edition
- Answers in C++ and Java
- This is a good warm-up for Cracking the Coding Interview
- Not too difficult. Most problems may be easier than what you'll see in an interview (from what I've read)
-
Cracking the Coding Interview, 6th Edition
- answers in Java
If you have tons of extra time:
Choose one:
- Elements of Programming Interviews (C++ version)
- Elements of Programming Interviews in Python
- Elements of Programming Interviews (Java version)
- Companion Project - Method Stub and Test Cases for Every Problem in the Book
Don't Make My Mistakes
This list grew over many months, and yes, it got out of hand.
Here are some mistakes I made so you'll have a better experience. And you'll save months of time.
1. You Won't Remember it All
I watched hours of videos and took copious notes, and months later there was much I didn't remember. I spent 3 days going
through my notes and making flashcards, so I could review. I didn't need all of that knowledge.
Please, read so you won't make my mistakes:
Retaining Computer Science Knowledge.
2. Use Flashcards
To solve the problem, I made a little flashcard site where I could add flashcards of 2 types: general and code.
Each card has a different formatting. I made a mobile-first website, so I could review on my phone or tablet, wherever I am.
Make your own for free:
I DON'T RECOMMEND using my flashcards. There are too many and most of them are trivia that you don't need.
But if you don't want to listen to me, here you go:
Keep in mind I went overboard and have cards covering everything from assembly language and Python trivia to machine learning and statistics.
It's way too much for what's required.
Note on flashcards: The first time you recognize you know the answer, don't mark it as known. You have to see the
same card and answer it several times correctly before you really know it. Repetition will put that knowledge deeper in
your brain.
An alternative to using my flashcard site is Anki, which has been recommended to me numerous times.
It uses a repetition system to help you remember. It's user-friendly, available on all platforms, and has a cloud sync system.
It costs $25 on iOS but is free on other platforms.
My flashcard database in Anki format: https://ankiweb.net/shared/info/25173560 (thanks @xiewenya).
Some students have mentioned formatting issues with white space that can be fixed by doing the following: open the deck, edit the card, click cards, select the "styling" radio button, and add the member "white-space: pre;" to the card class.
3. Do Coding Interview Questions While You're Learning
THIS IS VERY IMPORTANT.
Start doing coding interview questions while you're learning data structures and algorithms.
You need to apply what you're learning to solve problems, or you'll forget. I made this mistake.
Once you've learned a topic, and feel somewhat comfortable with it, for example, linked lists:
- Open one of the coding interview books (or coding problem websites, listed below)
- Do 2 or 3 questions regarding linked lists.
- Move on to the next learning topic.
- Later, go back and do another 2 or 3 linked list problems.
- Do this with each new topic you learn.
Keep doing problems while you're learning all this stuff, not after.
You're not being hired for knowledge, but how you apply the knowledge.
There are many resources for this, listed below. Keep going.
4. Focus
There are a lot of distractions that can take up valuable time. Focus and concentration are hard. Turn on some music
without lyrics and you'll be able to focus pretty well.
What you won't see covered
These are prevalent technologies but not part of this study plan:
- Javascript
- HTML, CSS, and other front-end technologies
- SQL
The Daily Plan
This course goes over a lot of subjects. Each will probably take you a few days, or maybe even a week or more. It depends on your schedule.
Each day, take the next subject in the list, watch some videos about that subject, and then write an implementation
of that data structure or algorithm in the language you chose for this course.
You can see my code here:
You don't need to memorize every algorithm. You just need to be able to understand it enough to be able to write your own implementation.
Coding Question Practice
Why is this here? I'm not ready to interview.
Why you need to practice doing programming problems:
- Problem recognition, and where the right data structures and algorithms fit in
- Gathering requirements for the problem
- Talking your way through the problem like you will in the interview
- Coding on a whiteboard or paper, not a computer
- Coming up with time and space complexity for your solutions (see Big-O below)
- Testing your solutions
There is a great intro for methodical, communicative problem-solving in an interview. You'll get this from the programming
interview books, too, but I found this outstanding:
Algorithm design canvas
Write code on a whiteboard or paper, not a computer. Test with some sample inputs. Then type it and test it out on a computer.
If you don't have a whiteboard at home, pick up a large drawing pad from an art store. You can sit on the couch and practice.
This is my "sofa whiteboard". I added the pen in the photo just for scale. If you use a pen, you'll wish you could erase.
Gets messy quickly. I use a pencil and eraser.

Coding question practice is not about memorizing answers to programming problems.
Coding Problems
Don't forget your key coding interview books here.
Solving Problems:
Coding Interview Question Videos:
- IDeserve (88 videos)
- Tushar Roy (5 playlists)
- Super for walkthroughs of problem solutions
- Nick White - LeetCode Solutions (187 Videos)
- Good explanations of the solution and the code
- You can watch several in a short time
- FisherCoder - LeetCode Solutions
Challenge/Practice sites:
- LeetCode
- My favorite coding problem site. It's worth the subscription money for the 1-2 months you'll likely be preparing.
- See Nick White and FisherCoder Videos above for code walk-throughs.
- HackerRank
- TopCoder
- Codeforces
- Codility
- Geeks for Geeks
- AlgoExpert
- Created by Google engineers, this is also an excellent resource to hone your skills.
- Project Euler
- very math-focused, and not really suited for coding interviews
Let's Get Started
Alright, enough talk, let's learn!
But don't forget to do coding problems from above while you learn!
Algorithmic complexity / Big-O / Asymptotic analysis
- Nothing to implement here, you're just watching videos and taking notes! Yay!
- There are a lot of videos here. Just watch enough until you understand it. You can always come back and review.
- Don't worry if you don't understand all the math behind it.
- You just need to understand how to express the complexity of an algorithm in terms of Big-O.
Well, that's about enough of that.
When you go through "Cracking the Coding Interview", there is a chapter on this, and at the end there is a quiz to see
if you can identify the runtime complexity of different algorithms. It's a super review and test.
Data Structures
-
Arrays
-
-
- can allocate int array under the hood, just not use its features
- start with 16, or if the starting number is greater, use power of 2 - 16, 32, 64, 128
-
- when you reach capacity, resize to double the size
- when popping an item, if the size is 1/4 of capacity, resize to half
-
-
- O(1) to add/remove at end (amortized for allocations for more space), index, or update
- O(n) to insert/remove elsewhere
-
- contiguous in memory, so proximity helps performance
- space needed = (array capacity, which is >= n) * size of item, but even if 2n, still O(n)
-
Linked Lists
-
Stack
-
Queue
-
- enqueue(value) - adds value at a position at the tail
- dequeue() - returns value and removes least recently added element (front)
- empty()
-
- enqueue(value) - adds item at end of available storage
- dequeue() - returns value and removes least recently added element
- empty()
- full()
-
- a bad implementation using a linked list where you enqueue at the head and dequeue at the tail would be O(n)
because you'd need the next to last element, causing a full traversal of each dequeue - enqueue: O(1) (amortized, linked list and array [probing])
- dequeue: O(1) (linked list and array)
- empty: O(1) (linked list and array)
- a bad implementation using a linked list where you enqueue at the head and dequeue at the tail would be O(n)
-
-
Hash table
-
-
- hash(k, m) - m is the size of the hash table
- add(key, value) - if the key already exists, update value
- exists(key)
- get(key)
- remove(key)
-
More Knowledge
-
Binary search
-
- binary search (on a sorted array of integers)
- binary search using recursion
-
-
Bitwise operations
-
- you should know many of the powers of 2 from (2^1 to 2^16 and 2^32)
-
-
Trees
-
Trees - Intro
-
- BFS notes:
- level order (BFS, using queue)
- time complexity: O(n)
- space complexity: best: O(1), worst: O(n/2)=O(n)
- DFS notes:
- time complexity: O(n)
- space complexity:
best: O(log n) - avg. height of tree
worst: O(n) - inorder (DFS: left, self, right)
- postorder (DFS: left, right, self)
- preorder (DFS: self, left, right)
- BFS notes:
-
-
Binary search trees: BSTs
- C/C++:
-
- C/C++:
-
Heap / Priority Queue / Binary Heap
- visualized as a tree, but is usually linear in storage (array, linked list)
-
Sorting
-
- Implement sorts & know best case/worst case, average complexity of each:
- no bubble sort - it's terrible - O(n^2), except when n <= 16
-
- I wouldn't recommend sorting a linked list, but merge sort is doable.
- Merge Sort For Linked List
- Implement sorts & know best case/worst case, average complexity of each:
-
For heapsort, see the Heap data structure above. Heap sort is great, but not stable
-
-
-
-
-
-
-
- Selection sort and insertion sort are both O(n^2) average and worst-case
- For heapsort, see Heap data structure above
-
-
As a summary, here is a visual representation of 15 sorting algorithms.
If you need more detail on this subject, see the "Sorting" section in Additional Detail on Some Subjects
Graphs
Graphs can be used to represent many problems in computer science, so this section is long, like trees and sorting.
-
Notes:
- There are 4 basic ways to represent a graph in memory:
- objects and pointers
- adjacency matrix
- adjacency list
- adjacency map
- Familiarize yourself with each representation and its pros & cons
- BFS and DFS - know their computational complexity, their trade-offs, and how to implement them in real code
- When asked a question, look for a graph-based solution first, then move on if none
- There are 4 basic ways to represent a graph in memory:
-
-
-
-
Full Coursera Course:
-
I'll implement:
- DFS-based algorithms (see Aduni videos above):
- DFS-based algorithms (see Aduni videos above):
Even More Knowledge
-
Recursion
-
- When it is appropriate to use it?
- How is tail recursion better than not?
-
-
Dynamic Programming
- You probably won't see any dynamic programming problems in your interview, but it's worth being able to recognize a
problem as being a candidate for dynamic programming. - This subject can be pretty difficult, as each DP soluble problem must be defined as a recursion relation, and coming up with it can be tricky.
- I suggest looking at many examples of DP problems until you have a solid understanding of the pattern involved.
-
-
-
- You probably won't see any dynamic programming problems in your interview, but it's worth being able to recognize a
-
Design patterns
-
-
- I know the canonical book is "Design Patterns: Elements of Reusable Object-Oriented Software", but Head First is great for beginners to OO.
- Handy reference: 101 Design Patterns & Tips for Developers
-
-
Combinatorics (n choose k) & Probability
-
- Course layout:
- Just the videos - 41 (each are simple and each are short):
- Course layout:
-
-
NP, NP-Complete and Approximation Algorithms
- Know about the most famous classes of NP-complete problems, such as the traveling salesman and the knapsack problem,
and be able to recognize them when an interviewer asks you them in disguise. - Know what NP-complete means.
-
-
- Peter Norvig discusses near-optimal solutions to the traveling salesman problem:
- Pages 1048 - 1140 in CLRS if you have it.
- Know about the most famous classes of NP-complete problems, such as the traveling salesman and the knapsack problem,
-
How computers process a program
-
Caches
-
-
Processes and Threads
-
- for processes and threads see videos 1-11
- Operating Systems and System Programming (video)
- What Is The Difference Between A Process And A Thread?
- Covers:
- Processes, Threads, Concurrency issues
- Difference between processes and threads
- Processes
- Threads
- Locks
- Mutexes
- Semaphores
- Monitors
- How do they work?
- Deadlock
- Livelock
- CPU activity, interrupts, context switching
- Modern concurrency constructs with multicore processors
- Paging, segmentation, and virtual memory (video)
- Interrupts (video)
- Process resource needs (memory: code, static storage, stack, heap, and also file descriptors, i/o)
- Thread resource needs (shares above (minus stack) with other threads in the same process but each has its own PC, stack counter, registers, and stack)
- Forking is really copy on write (read-only) until the new process writes to memory, then it does a full copy.
- Context switching
- Processes, Threads, Concurrency issues
-
-
Testing
- To cover:
- how unit testing works
- what are mock objects
- what is integration testing
- what is dependency injection
-
- To cover:
-
String searching & manipulations
If you need more detail on this subject, see the "String Matching" section in Additional Detail on Some Subjects.
-
-
Tries
- Note there are different kinds of tries. Some have prefixes, some don't, and some use strings instead of bits
to track the path - I read through the code, but will not implement
-
-
- Note there are different kinds of tries. Some have prefixes, some don't, and some use strings instead of bits
-
Floating Point Numbers
-
Unicode
-
Endianness
-
- Very technical talk for kernel devs. Don't worry if most is over your head.
- The first half is enough.
-
-
Networking
- If you have networking experience or want to be a reliability engineer or operations engineer, expect questions
- Otherwise, this is just good to know
-
Final Review
This section will have shorter videos that you can watch pretty quickly to review most of the important concepts.
It's nice if you want a refresher often.
Update Your Resume
- See Resume prep information in the books: "Cracking The Coding Interview" and "Programming Interviews Exposed"
- "This Is What A GOOD Resume Should Look Like" by Gayle McDowell (author of Cracking the Coding Interview),
- Note by the author: "This is for a US-focused resume. CVs for India and other countries have different expectations, although many of the points will be the same."
- "Step-by-step resume guide" by Tech Interview Handbook
- Detailed guide on how to set up your resume from scratch, write effective resume content, optimize it, and test your resume
Interview Process & General Interview Prep
-
-
-
- Prep Courses:
- Python for Data Structures, Algorithms, and Interviews (paid course):
- A Python-centric interview prep course that covers data structures, algorithms, mock interviews, and much more.
- Intro to Data Structures and Algorithms using Python (Udacity free course):
- A free Python-centric data structures and algorithms course.
- Data Structures and Algorithms Nanodegree! (Udacity paid Nanodegree):
- Get hands-on practice with over 100 data structures and algorithm exercises and guidance from a dedicated mentor to help prepare you for interviews and on-the-job scenarios.
- Grokking the Behavioral Interview (Educative free course):
- Many times, it’s not your technical competency that holds you back from landing your dream job, it’s how you perform on the behavioral interview.
- AlgoMonster (paid course with free content):
- The crash course for LeetCode. Covers all the patterns condensed from thousands of questions.
- Python for Data Structures, Algorithms, and Interviews (paid course):
Mock Interviews:
- Gainlo.co: Mock interviewers from big companies - I used this and it helped me relax for the phone screen and on-site interview
- Pramp: Mock interviews from/with peers - a peer-to-peer model to practice interviews
- interviewing.io: Practice mock interview with senior engineers - anonymous algorithmic/systems design interviews with senior engineers from FAANG anonymously
- Meetapro: Mock interviews with top FAANG interviewers - an Airbnb-style mock interview/coaching platform.
- Hello Interview: Mock Interviews with Expert Coaches and AI - interview directly with AI or with FAANG staff engineers and managers.
- Codemia: Practice system design problems with AI or community solutions and feedback - Practice system design problems via AI practice tool. Share your solution with the community to get human feedback as well.
Be thinking of for when the interview comes
Think of about 20 interview questions you'll get, along with the lines of the items below. Have at least one answer for each.
Have a story, not just data, about something you accomplished.
- Why do you want this job?
- What's a tough problem you've solved?
- Biggest challenges faced?
- Best/worst designs seen?
- Ideas for improving an existing product
- How do you work best, as an individual and as part of a team?
- Which of your skills or experiences would be assets in the role and why?
- What did you most enjoy at [job x / project y]?
- What was the biggest challenge you faced at [job x / project y]?
- What was the hardest bug you faced at [job x / project y]?
- What did you learn at [job x / project y]?
- What would you have done better at [job x / project y]?
Have questions for the interviewer
Some of mine (I already may know the answers, but want their opinion or team perspective):
- How large is your team?
- What does your dev cycle look like? Do you do waterfall/sprints/agile?
- Are rushes to deadlines common? Or is there flexibility?
- How are decisions made in your team?
- How many meetings do you have per week?
- Do you feel your work environment helps you concentrate?
- What are you working on?
- What do you like about it?
- What is the work life like?
- How is the work/life balance?
Once You've Got The Job
Congratulations!
Keep learning.
You're never really done.
*****************************************************************************************************
*****************************************************************************************************
Everything below this point is optional. It is NOT needed for an entry-level interview.
However, by studying these, you'll get greater exposure to more CS concepts and will be better prepared for
any software engineering job. You'll be a much more well-rounded software engineer.
*****************************************************************************************************
*****************************************************************************************************
Additional Books
These are here so you can dive into a topic you find interesting.
- The Unix Programming Environment
- An oldie but a goodie
- The Linux Command Line: A Complete Introduction
- A modern option
- TCP/IP Illustrated Series
- Head First Design Patterns
- A gentle introduction to design patterns
- Design Patterns: Elements of Reusable Object-Oriented Software
- AKA the "Gang Of Four" book or GOF
- The canonical design patterns book
- Algorithm Design Manual (Skiena)
- As a review and problem-recognition
- The algorithm catalog portion is well beyond the scope of difficulty you'll get in an interview
- This book has 2 parts:
- Class textbook on data structures and algorithms
- Pros:
- Is a good review as any algorithms textbook would be
- Nice stories from his experiences solving problems in industry and academia
- Code examples in C
- Cons:
- Can be as dense or impenetrable as CLRS, and in some cases, CLRS may be a better alternative for some subjects
- Chapters 7, 8, and 9 can be painful to try to follow, as some items are not explained well or require more brain than I have
- Don't get me wrong: I like Skiena, his teaching style, and mannerisms, but I may not be Stony Brook material
- Pros:
- Algorithm catalog:
- This is the real reason you buy this book.
- This book is better as an algorithm reference, and not something you read cover to cover.
- Class textbook on data structures and algorithms
- Can rent it on Kindle
- Answers:
- Errata
- Algorithm (Jeff Erickson)
- Write Great Code: Volume 1: Understanding the Machine
- The book was published in 2004, and is somewhat outdated, but it's a terrific resource for understanding a computer in brief
- The author invented HLA, so take mentions and examples in HLA with a grain of salt. Not widely used, but decent examples of what assembly looks like
- These chapters are worth the read to give you a nice foundation:
- Chapter 2 - Numeric Representation
- Chapter 3 - Binary Arithmetic and Bit Operations
- Chapter 4 - Floating-Point Representation
- Chapter 5 - Character Representation
- Chapter 6 - Memory Organization and Access
- Chapter 7 - Composite Data Types and Memory Objects
- Chapter 9 - CPU Architecture
- Chapter 10 - Instruction Set Architecture
- Chapter 11 - Memory Architecture and Organization
- Introduction to Algorithms
- Important: Reading this book will only have limited value. This book is a great review of algorithms and data structures, but won't teach you how to write good code. You have to be able to code a decent solution efficiently
- AKA CLR, sometimes CLRS, because Stein was late to the game
- Computer Architecture, Sixth Edition: A Quantitative Approach
- For a richer, more up-to-date (2017), but longer treatment
System Design, Scalability, Data Handling
You can expect system design questions if you have 4+ years of experience.
- Scalability and System Design are very large topics with many topics and resources, since
there is a lot to consider when designing a software/hardware system that can scale.
Expect to spend quite a bit of time on this - Considerations:
- Scalability
- Distill large data sets to single values
- Transform one data set to another
- Handling obscenely large amounts of data
- System design
- features sets
- interfaces
- class hierarchies
- designing a system under certain constraints
- simplicity and robustness
- tradeoffs
- performance analysis and optimization
- Scalability
-
-
-
- You don't need all of these. Just pick a few that interest you.
- For even more, see the "Mining Massive Datasets" video series in the Video Series section
-
- review: The System Design Primer
- System Design from HiredInTech
- cheat sheet
- flow:
- Understand the problem and scope:
- Define the use cases, with the interviewer's help
- Suggest additional features
- Remove items that the interviewer deems out of scope
- Assume high availability is required, add as a use case
- Think about constraints:
- Ask how many requests per month
- Ask how many requests per second (they may volunteer it or make you do the math)
- Estimate reads vs. writes percentage
- Keep the 80/20 rule in mind when estimating
- How much data is written per second
- Total storage required over 5 years
- How much data read per second
- Abstract design:
- Layers (service, data, caching)
- Infrastructure: load balancing, messaging
- Rough overview of any key algorithm that drives the service
- Consider bottlenecks and determine solutions
- Understand the problem and scope:
- Exercises:
Additional Learning
I added them to help you become a well-rounded software engineer and to be aware of certain
technologies and algorithms, so you'll have a bigger toolbox.
-
Compilers
-
Emacs and vi(m)
- Familiarize yourself with a UNIX-based code editor
- vi(m):
- emacs:
- The Absolute Beginner's Guide to Emacs (video by David Wilson)
- The Absolute Beginner's Guide to Emacs (notes by David Wilson)
-
Unix/Linux command line tools
- I filled in the list below from good tools.
- bash
- cat
- grep
- sed
- awk
- curl or wget
- sort
- tr
- uniq
- strace
- tcpdump
- Essential Linux Commands Tutorial
-
DevOps
-
Information theory (videos)
- Khan Academy
- More about Markov processes:
- See more in the MIT 6.050J Information and Entropy series below
-
Parity & Hamming Code (videos)
- Intro
- Parity
- Hamming Code:
- Error Checking
-
Entropy
- Also see the videos below
- Make sure to watch information theory videos first
- Information Theory, Claude Shannon, Entropy, Redundancy, Data Compression & Bits (video)
-
Cryptography
- Also see the videos below
- Make sure to watch information theory videos first
- Khan Academy Series
- Cryptography: Hash Functions
- Cryptography: Encryption
-
Compression
- Make sure to watch information theory videos first
- Computerphile (videos):
- Compressor Head videos
- (optional) Google Developers Live: GZIP is not enough!
-
Computer Security
-
Garbage collection
-
Parallel Programming
-
Messaging, Serialization, and Queueing Systems
-
A*
-
Fast Fourier Transform
-
Bloom Filter
- Given a Bloom filter with m bits and k hashing functions, both insertion and membership testing are O(k)
- Bloom Filters (video)
- Bloom Filters | Mining of Massive Datasets | Stanford University (video)
- Tutorial
- How To Write A Bloom Filter App
-
HyperLogLog
-
Locality-Sensitive Hashing
- Used to determine the similarity of documents
- The opposite of MD5 or SHA which are used to determine if 2 documents/strings are exactly the same
- Simhashing (hopefully) made simple
-
van Emde Boas Trees
-
Augmented Data Structures
-
Balanced search trees
-
Know at least one type of balanced binary tree (and know how it's implemented):
-
"Among balanced search trees, AVL and 2/3 trees are now passé and red-black trees seem to be more popular.
A particularly interesting self-organizing data structure is the splay tree, which uses rotations
to move any accessed key to the root." - Skiena -
Of these, I chose to implement a splay tree. From what I've read, you won't implement a
balanced search tree in your interview. But I wanted exposure to coding one up
and let's face it, splay trees are the bee's knees. I did read a lot of red-black tree code- Splay tree: insert, search, delete functions
If you end up implementing a red/black tree try just these: - Search and insertion functions, skipping delete
- Splay tree: insert, search, delete functions
-
I want to learn more about B-Tree since it's used so widely with very large data sets
-
AVL trees
- In practice:
From what I can tell, these aren't used much in practice, but I could see where they would be:
The AVL tree is another structure supporting O(log n) search, insertion, and removal. It is more rigidly
balanced than red–black trees, leading to slower insertion and removal but faster retrieval. This makes it
attractive for data structures that may be built once and loaded without reconstruction, such as language
dictionaries (or program dictionaries, such as the opcodes of an assembler or interpreter) - MIT AVL Trees / AVL Sort (video)
- AVL Trees (video)
- AVL Tree Implementation (video)
- Split And Merge
- [Review] AVL Trees (playlist) in 19 minutes (video)
- In practice:
-
Splay trees
- In practice:
Splay trees are typically used in the implementation of caches, memory allocators, routers, garbage collectors,
data compression, ropes (replacement of string used for long text strings), in Windows NT (in the virtual memory,
networking and file system code) etc - CS 61B: Splay Trees (video)
- MIT Lecture: Splay Trees:
- Gets very mathy, but watch the last 10 minutes for sure.
- Video
- In practice:
-
Red/black trees
- These are a translation of a 2-3 tree (see below).
- In practice:
Red–black trees offer worst-case guarantees for insertion time, deletion time, and search time.
Not only does this make them valuable in time-sensitive applications such as real-time applications,
but it makes them valuable building blocks in other data structures that provide worst-case guarantees;
for example, many data structures used in computational geometry can be based on red-black trees, and
the Completely Fair Scheduler used in current Linux kernels uses red–black trees. In version 8 of Java,
the Collection HashMap has been modified such that instead of using a LinkedList to store identical elements with poor
hashcodes, a Red-Black tree is used - Aduni - Algorithms - Lecture 4 (link jumps to the starting point) (video)
- Aduni - Algorithms - Lecture 5 (video)
- Red-Black Tree
- An Introduction To Binary Search And Red Black Tree
- [Review] Red-Black Trees (playlist) in 30 minutes (video)
-
2-3 search trees
- In practice:
2-3 trees have faster inserts at the expense of slower searches (since height is more compared to AVL trees). - You would use 2-3 trees very rarely because its implementation involves different types of nodes. Instead, people use Red-Black trees.
- 23-Tree Intuition and Definition (video)
- Binary View of 23-Tree
- 2-3 Trees (student recitation) (video)
- In practice:
-
2-3-4 Trees (aka 2-4 trees)
- In practice:
For every 2-4 trees, there are corresponding red–black trees with data elements in the same order. The insertion and deletion
operations on 2-4 trees are also equivalent to color-flipping and rotations in red–black trees. This makes 2-4 trees an
important tool for understanding the logic behind red-black trees, and this is why many introductory algorithm texts introduce
2-4 trees just before red–black trees, even though 2-4 trees are not often used in practice. - CS 61B Lecture 26: Balanced Search Trees (video)
- Bottom Up 234-Trees (video)
- Top Down 234-Trees (video)
- In practice:
-
N-ary (K-ary, M-ary) trees
- note: the N or K is the branching factor (max branches)
- binary trees are a 2-ary tree, with branching factor = 2
- 2-3 trees are 3-ary
- K-Ary Tree
-
B-Trees
- Fun fact: it's a mystery, but the B could stand for Boeing, Balanced, or Bayer (co-inventor).
- In Practice:
B-trees are widely used in databases. Most modern filesystems use B-trees (or Variants). In addition to
its use in databases, the B-tree is also used in filesystems to allow quick random access to an arbitrary
block in a particular file. The basic problem is turning the file block address into a disk block
(or perhaps to a cylinder head sector) address - B-Tree
- B-Tree Datastructure
- Introduction to B-Trees (video)
- B-Tree Definition and Insertion (video)
- B-Tree Deletion (video)
- MIT 6.851 - Memory Hierarchy Models (video)
- covers cache-oblivious B-Trees, very interesting data structures
- the first 37 minutes are very technical, and may be skipped (B is block size, cache line size) - [Review] B-Trees (playlist) in 26 minutes (video)
-
-
k-D Trees
- Great for finding a number of points in a rectangle or higher-dimensional object
- A good fit for k-nearest neighbors
- kNN K-d tree algorithm (video)
-
Skip lists
- "These are somewhat of a cult data structure" - Skiena
- Randomization: Skip Lists (video)
- For animations and a little more detail
-
Network Flows
-
Disjoint Sets & Union Find
-
Math for Fast Processing
-
Treap
- Combination of a binary search tree and a heap
- Treap
- Data Structures: Treaps explained (video)
- Applications in set operations
-
Linear Programming (videos)
-
Geometry, Convex hull (videos)
-
Discrete math
Additional Detail on Some Subjects
I added these to reinforce some ideas already presented above, but didn't want to include them
above because it's just too much. It's easy to overdo it on a subject.
You want to get hired in this century, right?
-
SOLID
-
Union-Find
-
More Dynamic Programming (videos)
- 6.006: Dynamic Programming I: Fibonacci, Shortest Paths
- 6.006: Dynamic Programming II: Text Justification, Blackjack
- 6.006: DP III: Parenthesization, Edit Distance, Knapsack
- 6.006: DP IV: Guitar Fingering, Tetris, Super Mario Bros.
- 6.046: Dynamic Programming & Advanced DP
- 6.046: Dynamic Programming: All-Pairs Shortest Paths
- 6.046: Dynamic Programming (student recitation)
-
Advanced Graph Processing (videos)
-
MIT Probability (mathy, and go slowly, which is good for mathy things) (videos):
-
String Matching
- Rabin-Karp (videos):
- Knuth-Morris-Pratt (KMP):
- Boyer–Moore string search algorithm
- Coursera: Algorithms on Strings
- starts off great, but by the time it gets past KMP it gets more complicated than it needs to be
- nice explanation of tries
- can be skipped
-
Sorting
- Stanford lectures on sorting:
- Shai Simonson:
- Steven Skiena lectures on sorting:
-
NAND To Tetris: Build a Modern Computer from First Principles
Video Series
Sit back and enjoy.
-
List of individual Dynamic Programming problems (each is short)
-
Excellent - MIT Calculus Revisited: Single Variable Calculus
-
Skiena lectures from Algorithm Design Manual - CSE373 2020 - Analysis of Algorithms (26 videos)
-
Carnegie Mellon - Computer Architecture Lectures (39 videos)
-
MIT 6.042J: Mathematics for Computer Science, Fall 2010 (25 videos)
Computer Science Courses
Algorithms implementation
Papers
- Love classic papers?
- 1978: Communicating Sequential Processes
- 2003: The Google File System
- replaced by Colossus in 2012
- 2004: MapReduce: Simplified Data Processing on Large Clusters
- mostly replaced by Cloud Dataflow?
- 2006: Bigtable: A Distributed Storage System for Structured Data
- 2006: The Chubby Lock Service for Loosely-Coupled Distributed Systems
- 2007: Dynamo: Amazon’s Highly Available Key-value Store
- The Dynamo paper kicked off the NoSQL revolution
- 2007: What Every Programmer Should Know About Memory (very long, and the author encourages skipping of some sections)
- 2012: AddressSanitizer: A Fast Address Sanity Checker:
- 2013: Spanner: Google’s Globally-Distributed Database:
- 2015: Continuous Pipelines at Google
- 2015: High-Availability at Massive Scale: Building Google’s Data Infrastructure for Ads
- 2015: How Developers Search for Code: A Case Study
- More papers: 1,000 papers
LICENSE
My Codex Skills
Skills Public
A collection of reusable development skills for Apple platforms, GitHub workflows, refactoring, diff review swarms, bug investigation swarms, code review, React performance work, and skill curation.
Overview
This repository contains focused, self-contained skills that help with recurring engineering tasks such as generating App Store release notes, debugging iOS apps, improving SwiftUI and React code, packaging macOS apps, running multi-agent diff reviews and bug hunts, reviewing and simplifying code changes, orchestrating larger refactors, and auditing what new skills a project actually needs.
Install: place these skill folders under $CODEX_HOME/skills
Skills
This repo currently includes 16 skills:
| Skill | Folder | Description |
|---|---|---|
| App Store Changelog | app-store-changelog |
Creates user-facing App Store release notes from git history by collecting changes since the last tag, filtering for user-visible work, and rewriting it into concise "What's New" bullets. |
| GitHub | github |
Uses the gh CLI to inspect and operate on GitHub issues, pull requests, workflow runs, and API data, including CI checks, run logs, and advanced queries. |
| iOS Debugger Agent | ios-debugger-agent |
Uses XcodeBuildMCP to build, launch, and debug the current iOS app on a booted simulator, including UI inspection, interaction, screenshots, and log capture. |
| macOS Menubar Tuist App | macos-menubar-tuist-app |
Builds, refactors, or reviews macOS menubar apps that use Tuist and SwiftUI, with emphasis on manifest ownership, store-layer architecture, and reliable local launch scripts. |
| macOS SwiftPM App Packaging (No Xcode) | macos-spm-app-packaging |
Scaffolds, builds, packages, signs, and optionally notarizes SwiftPM-based macOS apps without requiring an Xcode project. |
| Orchestrate Batch Refactor | orchestrate-batch-refactor |
Plans and executes larger refactor or rewrite efforts with dependency-aware parallel analysis and implementation using clearly scoped work packets. |
| Project Skill Audit | project-skill-audit |
Analyzes a project's past Codex sessions, memory, existing local skills, and conventions to recommend the highest-value new skills or updates to existing ones. |
| React Component Performance | react-component-performance |
Diagnoses slow React components by finding re-render churn, expensive render work, unstable props, and list bottlenecks, then suggests targeted optimizations and validation steps. |
| Bug Hunt Swarm | bug-hunt-swarm |
Runs a read-only four-agent bug investigation focused on reproduction, code-path tracing, regressors, and the fastest proof step, then returns a ranked root-cause path. |
| Review and Simplify Changes | review-and-simplify-changes |
Reviews a git diff or explicit file scope for reuse, code quality, efficiency, clarity, and standards issues, then optionally applies safe, behavior-preserving fixes. |
| Review Swarm | review-swarm |
Runs a read-only four-agent diff review focused on behavioral regressions, security risks, performance or reliability issues, and contract or test coverage gaps, then returns a prioritized fix path. |
| Swift Concurrency Expert | swift-concurrency-expert |
Reviews and fixes Swift 6.2+ concurrency issues such as actor isolation problems, Sendable violations, main-actor annotations, and data-race diagnostics. |
| SwiftUI Liquid Glass | swiftui-liquid-glass |
Implements, reviews, or refactors SwiftUI features to use the iOS 26+ Liquid Glass APIs correctly, with proper modifier ordering, grouping, interactivity, and fallbacks. |
| SwiftUI Performance Audit | swiftui-performance-audit |
Audits SwiftUI runtime performance from code and architecture, focusing on invalidation storms, identity churn, layout thrash, heavy render work, and profiling guidance. |
| SwiftUI UI Patterns | swiftui-ui-patterns |
Provides best practices and example-driven guidance for building SwiftUI screens and components, including navigation, sheets, app wiring, async state, and reusable UI patterns. |
| SwiftUI View Refactor | swiftui-view-refactor |
Refactors SwiftUI view files toward smaller subviews, MV-style data flow, stable view trees, explicit dependency injection, and correct Observation usage. |
Usage
Each skill is self-contained. Refer to the SKILL.md file in each skill directory for triggers, workflow guidance, examples, and supporting references.
Contributing
Skills are designed to be focused and reusable. When adding new skills, ensure they:
- Have a clear, single purpose
- Include comprehensive documentation
- Follow consistent patterns with existing skills
- Include reference materials when applicable
Vim-fork focused on extensibility and usability
![]()
![]()


Neovim is a project that seeks to aggressively refactor Vim in order to:
- Simplify maintenance and encourage contributions
- Split the work between multiple developers
- Enable advanced UIs without modifications to the core
- Maximize extensibility
See the Introduction wiki page and Roadmap
for more information.
Features
- Modern GUIs
- API access
from any language including C/C++, C#, Clojure, D, Elixir, Go, Haskell, Java/Kotlin,
JavaScript/Node.js, Julia, Lisp, Lua, Perl, Python, Racket, Ruby, Rust - Embedded, scriptable terminal emulator
- Asynchronous job control
- Shared data (shada) among multiple editor instances
- XDG base directories support
- Compatible with most Vim plugins, including Ruby and Python plugins
See :help nvim-features for the full list, and :help news for noteworthy changes in the latest version!
Install from package
Pre-built packages for Windows, macOS, and Linux are found on the
Releases page.
Managed packages are in Homebrew, Debian, Ubuntu, Fedora, Arch Linux, Void Linux, Gentoo, and more!
Install from source
See BUILD.md and supported platforms for details.
The build is CMake-based, but a Makefile is provided as a convenience.
After installing the dependencies, run the following command.
make CMAKE_BUILD_TYPE=RelWithDebInfo
sudo make install
To install to a non-default location:
make CMAKE_BUILD_TYPE=RelWithDebInfo CMAKE_INSTALL_PREFIX=/full/path/
make install
CMake hints for inspecting the build:
cmake --build build --target helplists all build targets.build/CMakeCache.txt(orcmake -LAH build/) contains the resolved values of all CMake variables.build/compile_commands.jsonshows the full compiler invocations for each translation unit.
Transitioning from Vim
See :help nvim-from-vim for instructions.
Project layout
├─ cmake/ CMake utils
├─ cmake.config/ CMake defines
├─ cmake.deps/ subproject to fetch and build dependencies (optional)
├─ runtime/ plugins and docs
├─ src/nvim/ application source code (see src/nvim/README.md)
│ ├─ api/ API subsystem
│ ├─ eval/ Vimscript subsystem
│ ├─ event/ event-loop subsystem
│ ├─ generators/ code generation (pre-compilation)
│ ├─ lib/ generic data structures
│ ├─ lua/ Lua subsystem
│ ├─ msgpack_rpc/ RPC subsystem
│ ├─ os/ low-level platform code
│ └─ tui/ built-in UI
└─ test/ tests (see test/README.md)
License
Neovim contributions since b17d96 are licensed under the
Apache 2.0 license, except for contributions copied from Vim (identified by the
vim-patch token). See LICENSE.txt for details.
Self-hosted AI accounting app. LLM analyzer for receipts, invoices, transactions with custom prompts and categories


🙏 I'm currently looking for a job! Here's my CV and my Github profile.
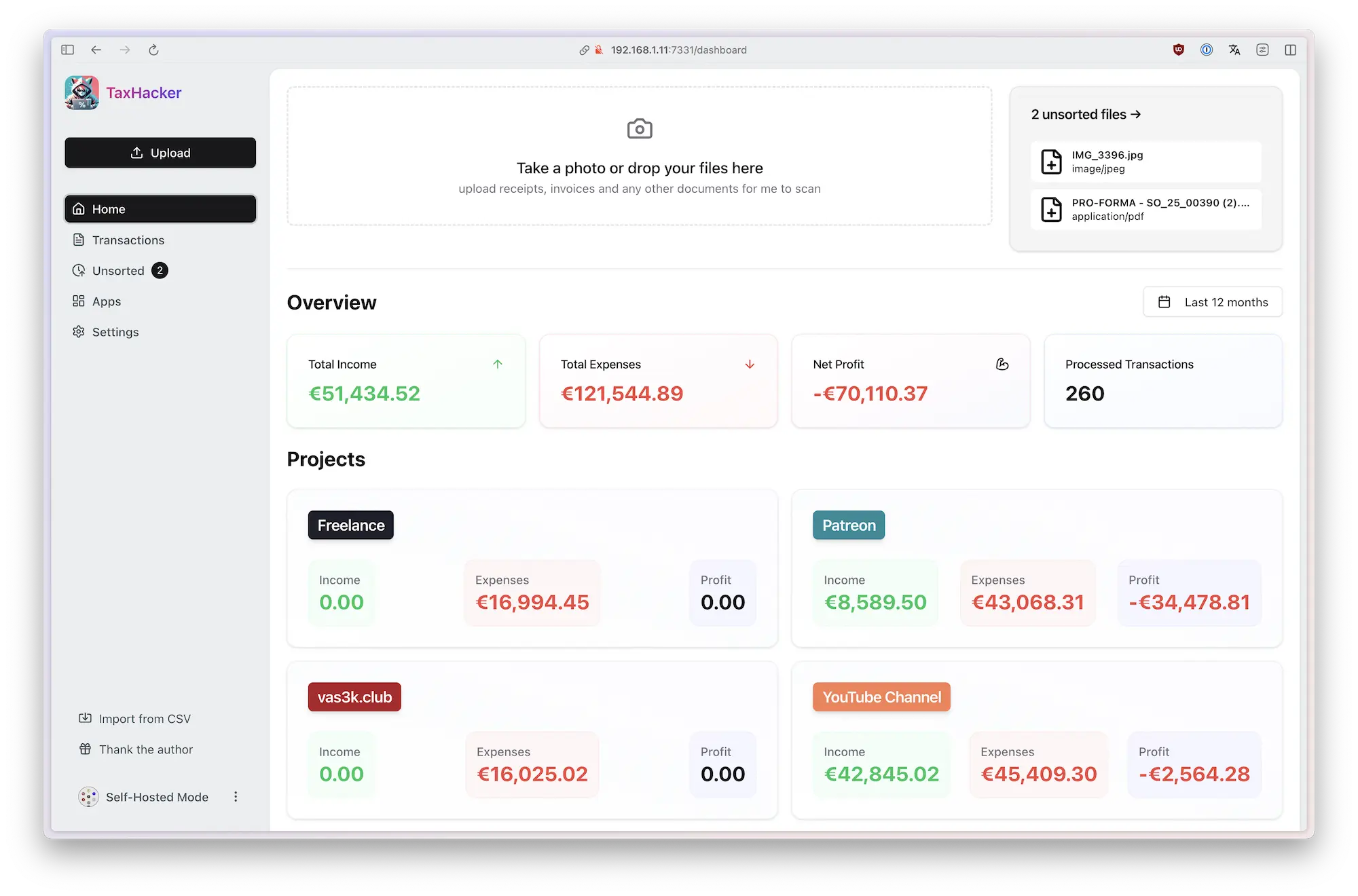
TaxHacker is a self-hosted accounting app designed for freelancers, indie hackers, and small businesses who want to save time and automate expense and income tracking using the power of modern AI.
Upload photos of receipts, invoices, or PDFs, and TaxHacker will automatically recognize and extract all the important data you need for accounting: product names, amounts, items, dates, merchants, taxes, and save it into a structured Excel-like database. You can even create custom fields with your own AI prompts to extract any specific information you need.
The app features automatic currency conversion (including crypto!) based on historical exchange rates from the transaction date. With built-in filtering, multi-project support, import/export capabilities, and custom categories, TaxHacker simplifies reporting and makes tax filing a bit easier.
Important
This project is still in early development. Use at your own risk! Star us to get notified about new features and bugfixes ⭐️
✨ Features
1 Analyze photos and invoices with AI
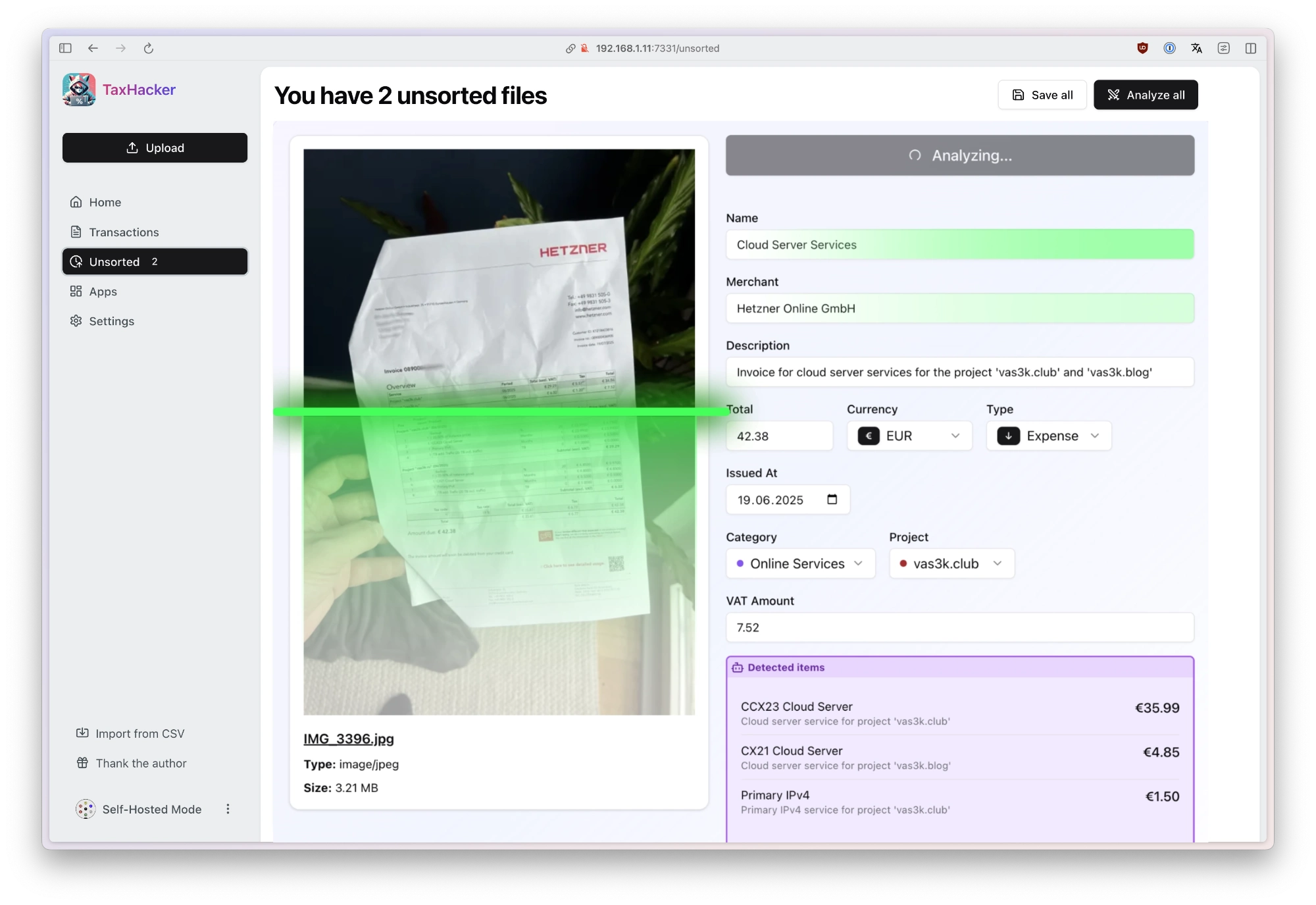
Snap a photo of any receipt or upload an invoice PDF, and TaxHacker will automatically recognize, extract, categorize, and store all the information in a structured database.
- Upload and organize your docs: Store multiple documents in "unsorted" until you're ready to process them manually or with AI assistance
- AI data extraction: Use AI to automatically pull key information like dates, amounts, vendors, and line items
- Auto-categorization: Transactions are automatically sorted into relevant categories based on their content
- Item splitting: Extract individual items from invoices and split them into separate transactions when needed
- Structured storage: Everything gets saved in an organized database for easy filtering and retrieval
- Customizable AI providers: Choose from OpenAI, Google Gemini, or Mistral (local LLM support coming soon)
TaxHacker works with a wide variety of documents, including store receipts, restaurant bills, invoices, bank statements, letters, even handwritten receipts. It handles any language and any currency with ease.
2 Multi-currency support with automatic conversion (even crypto!)
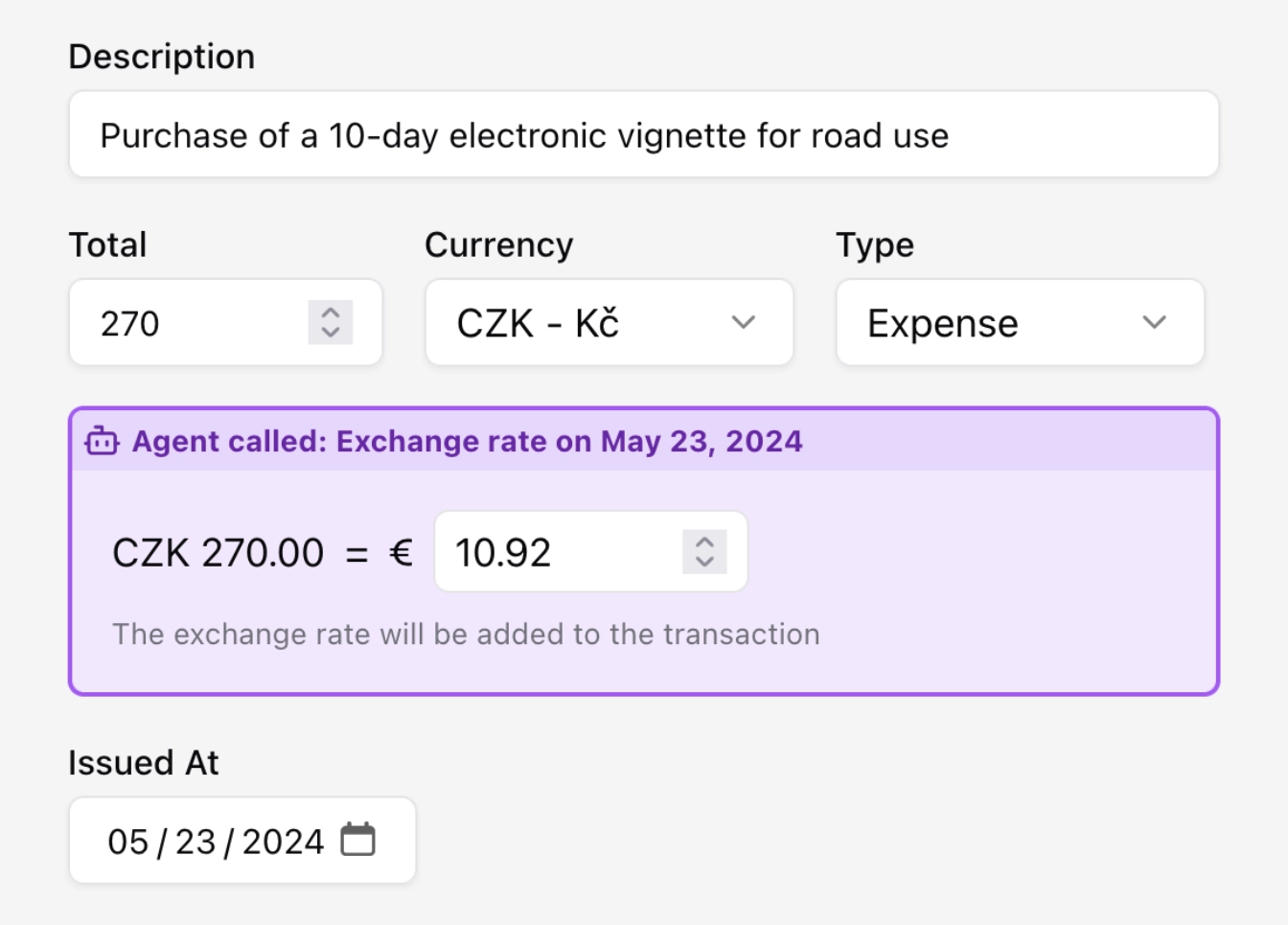
TaxHacker automatically detects currencies in your documents and converts them to your base currency using historical exchange rates.
- Foreight currency detection: Automatically identify the currency used in any document
- Historical rates: Get conversion rates from the actual transaction date
- All-world coverage: Support for 170+ world currencies and 14 popular cryptocurrencies (BTC, ETH, LTC, DOT, and more)
- Flexible input: Manual entry is always available when you need more control
3 Organize your transactions using fully customizable categories, projects and fields
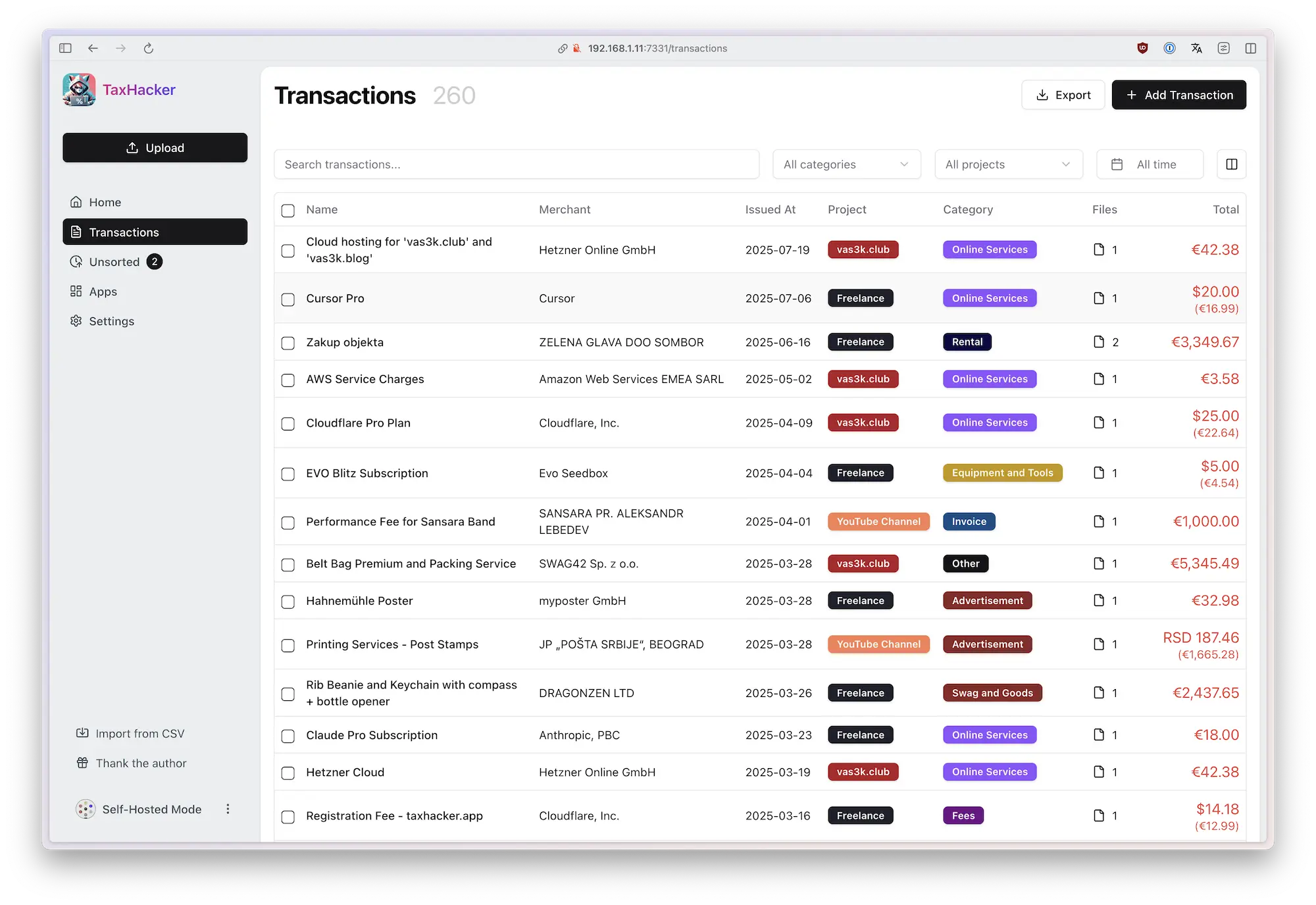
Adapt TaxHacker to your unique needs with unlimited customization options. Create custom fields, projects, and categories that better suit your specific needs, idustry standards or country.
- Custom categories and projecst: Create your own categories and projects to group your transactions in any convenient way
- Custom fields: You can create unlimited number of custom fields to extraxt more information from your invoices (it's like creating extra columns in Excel)
- Full-text search: Search through the actual content of recognized documents
- Advanced filtering: Find exactly what you need with search and filter options
- AI-powered extraction: Write your own prompts to extract any custom information from documents
- Bulk operations: Process multiple documents or transactions at once
4 Customize any LLM prompt. Even system ones
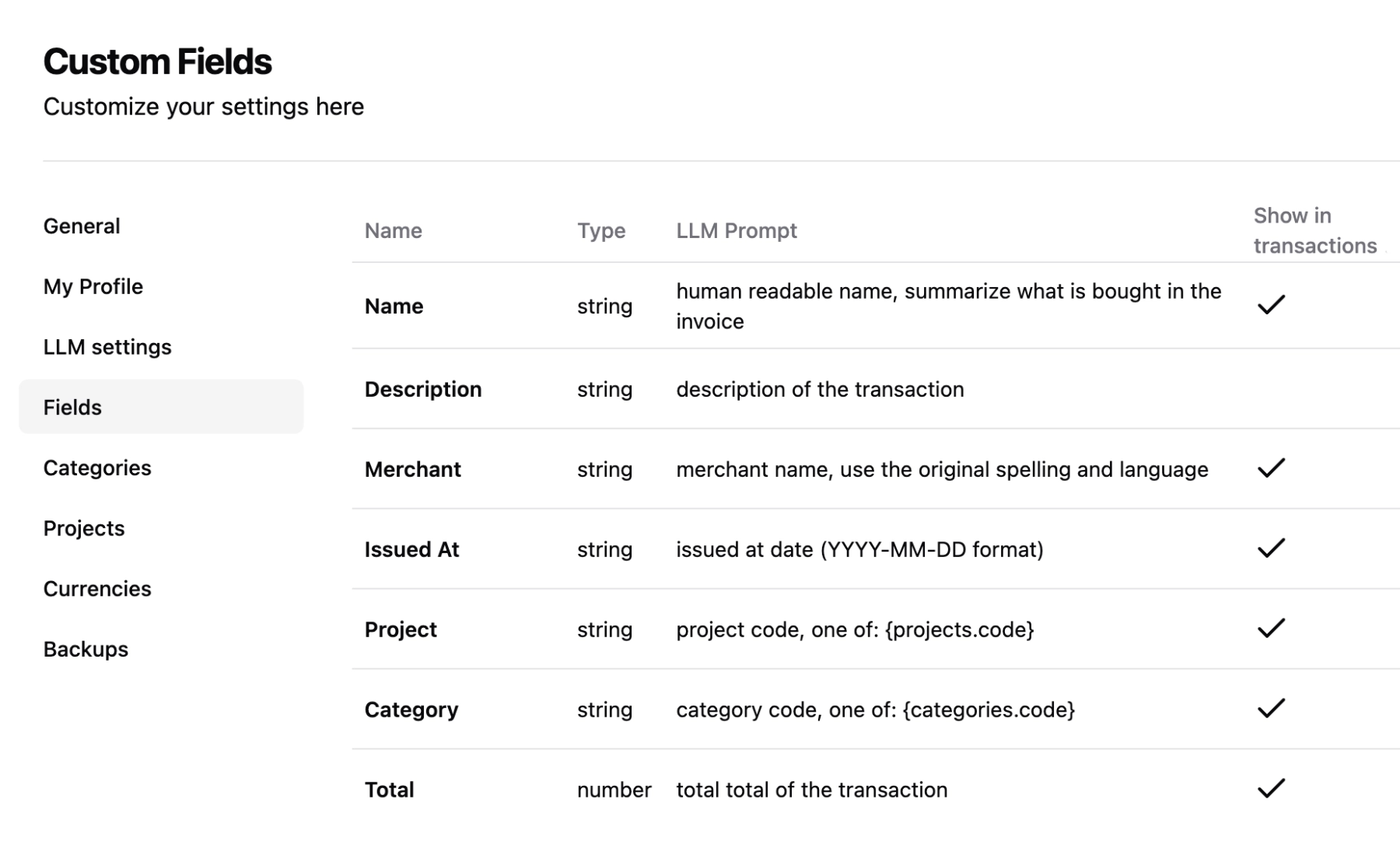
Take full control of how TaxHacker's AI processes your documents. Write custom AI prompts for fields, categories, and projects, or modify the built-in ones to match your specific needs.
- Customizable system prompts: Modify the general prompt template in settings to suit your business
- Field or project-specific prompts: Create custom extraction rules for your industry-specific documents
- Full control: Adjust field extraction priorities and naming conventions to match your workflow
- Industry optimization: Fine-tune the AI to understand your specific type of business documents
- Full transparency: Every aspect of the AI extraction process is under your control and can be changed right in settings
TaxHacker is 100% adaptable and tunable to your unique requirements — whether you need to extract emails, addresses, project codes, or any other custom information from your documents.
5 Flexible data filtering and export
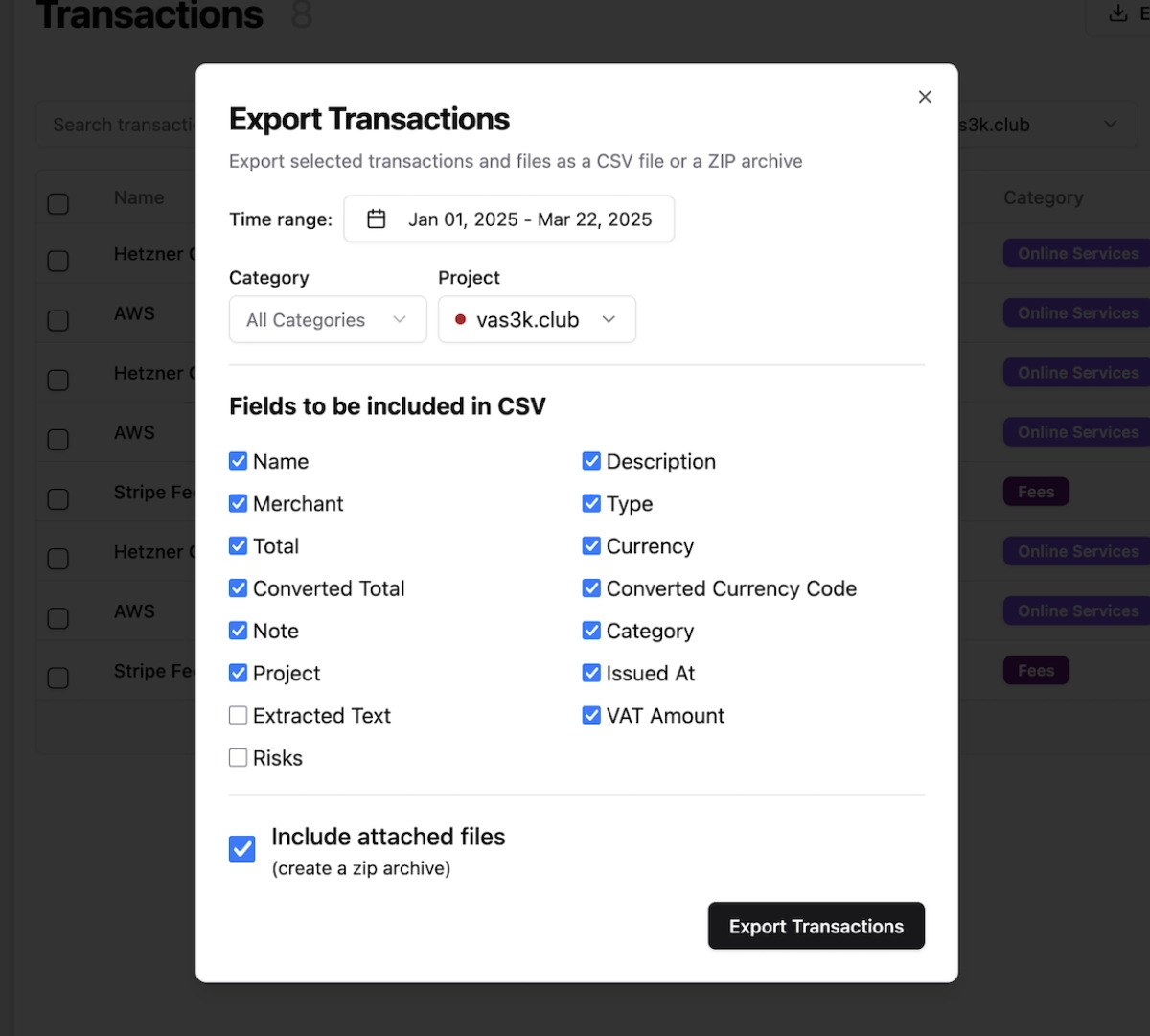
Once your documents are processed, easily view, filter, and export your complete transaction history exactly how you need it.
- Advanced filtering: Filter by date ranges, categories, projects, amounts, and any custom fields
- Flexible exports: Export filtered transactions to CSV with all attached documents included
- Tax-ready reports: Generate comprehensive reports for your accountant or tax advisor
- Data portability: Download complete data archives to migrate to other services—your data stays yours
6 Self-hosted mode for data privacy
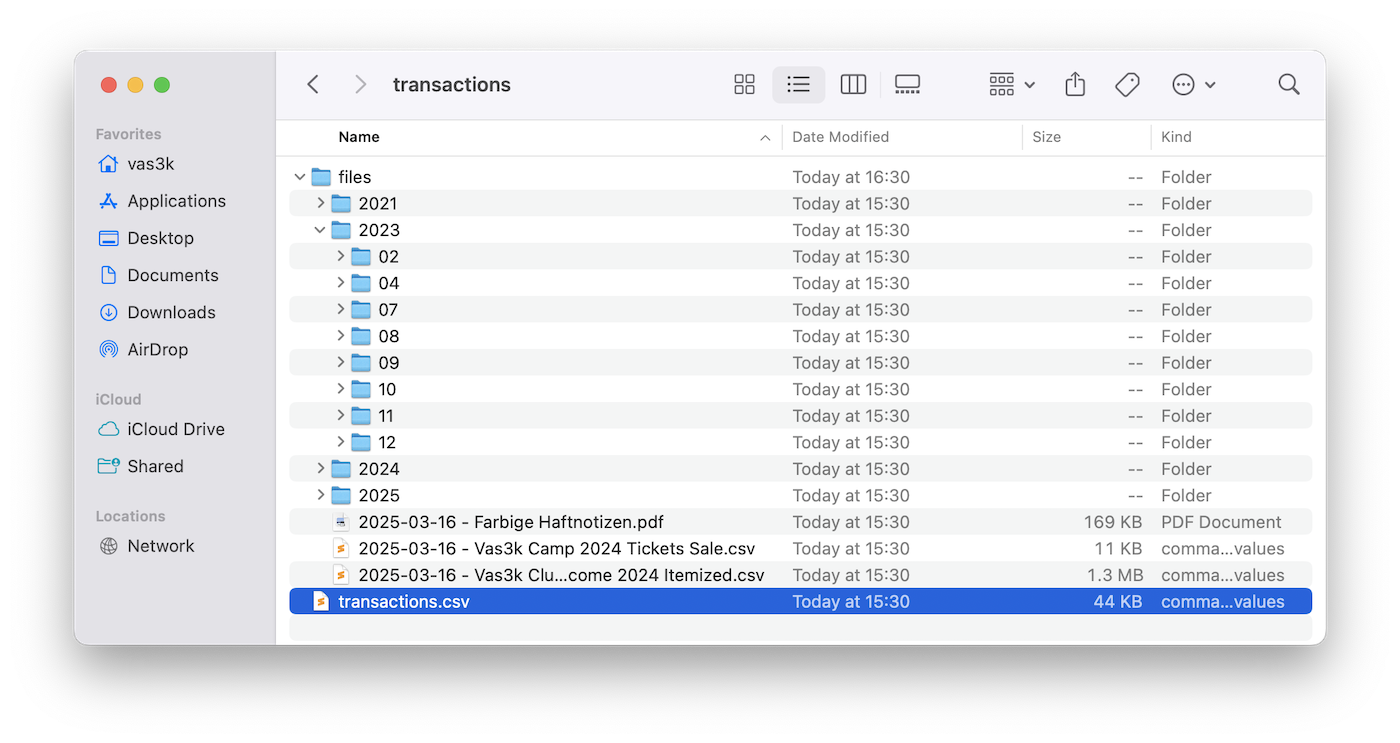
Keep complete control over your financial data with local storage and self-hosting options. TaxHacker respects your privacy and gives you full ownership of your information.
- Home server ready: Host on your own infrastructure for maximum privacy and control
- Docker native: Simple setup with provided Docker containers and compose files
- Data ownership: Your financial documents never leaves your control
- No vendor lock-in: Export everything and migrate whenever you want
- Transparent operations: Full access to source code and complete operational transparency
🛳 Deployment and Self-hosting
TaxHacker can be easily self-hosted on your own infrastructure for complete control over your data and application environment. We provide a Docker image and Docker Compose setup that makes deployment simple:
curl -O https://raw.githubusercontent.com/vas3k/TaxHacker/main/docker-compose.yml
docker compose up
The Docker Compose setup includes:
- TaxHacker application container
- PostgreSQL 17 database (or connect to your existing database)
- Automatic database migrations on startup
- Volume mounts for persistent data storage
- Production-ready configuration
New Docker images are automatically built and published with every release. You can use specific version tags (e.g., v1.0.0) or latest for the most recent version.
For advanced setups, you can customize the Docker Compose configuration to fit your infrastructure. The default configuration uses the pre-built image from GitHub Container Registry, but you can also build locally using the provided Dockerfile.
Example custom configuration:
services:
app:
image: ghcr.io/vas3k/taxhacker:latest
ports:
- "7331:7331"
environment:
- SELF_HOSTED_MODE=true
- UPLOAD_PATH=/app/data/uploads
- DATABASE_URL=postgresql://postgres:postgres@localhost:5432/taxhacker
volumes:
- ./data:/app/data
restart: unless-stopped
Environment Variables
Configure TaxHacker for your specific needs with these environment variables:
| Variable | Required | Description | Example |
|---|---|---|---|
UPLOAD_PATH |
Yes | Local directory for file uploads and storage | ./data/uploads |
DATABASE_URL |
Yes | PostgreSQL connection string | postgresql://user@localhost:5432/taxhacker |
PORT |
No | Port to run the application on | 7331 (default) |
BASE_URL |
No | Base URL for the application | http://localhost:7331 |
SELF_HOSTED_MODE |
No | Set to "true" for self-hosting: enables auto-login, custom API keys, and additional features | true |
DISABLE_SIGNUP |
No | Disable new user registration on your instance | false |
BETTER_AUTH_SECRET |
Yes | Secret key for authentication (minimum 16 characters) | your-secure-random-key |
You can also configure LLM provider settings in the application or via environment variables:
- OpenAI:
OPENAI_MODEL_NAMEandOPENAI_API_KEY - Google Gemini:
GOOGLE_MODEL_NAMEandGOOGLE_API_KEY - Mistral:
MISTRAL_MODEL_NAMEandMISTRAL_API_KEY
⌨️ Local Development
We use:
- Next.js 15+ for the frontend and API
- Prisma for database models and migrations
- PostgreSQL as the database (PostgreSQL 17+ recommended)
- Ghostscript and GraphicsMagick for PDF processing (install on macOS via
brew install gs graphicsmagick)
Set up your local development environment:
# Clone the repository
git clone https://github.com/vas3k/TaxHacker.git
cd TaxHacker
# Install dependencies
npm install
# Set up environment variables
cp .env.example .env
# Edit .env with your configuration
# Make sure to set DATABASE_URL to your PostgreSQL connection string
# Example: postgresql://user@localhost:5432/taxhacker
# Initialize the database
npx prisma generate && npx prisma migrate dev
# Start the development server
npm run dev
Visit http://localhost:7331 to see your local TaxHacker instance in action.
For a production build, instead of npm run dev use the following commands:
# Build the application
npm run build
# Start the production server
npm run start
🤝 Contributing
We welcome contributions to TaxHacker! Here's how you can help make it even better:
- 🐛 Bug Reports: File detailed issues when you encounter problems
- 💡 Feature Requests: Share your ideas for new features and improvements
- 🔧 Code Contributions: Submit pull requests to improve the application
- 📚 Documentation: Help improve documentation and guides
- 🎥 Content Creation: Videos, tutorials, and reviews help us reach more users!
All development happens on GitHub through issues and pull requests. We appreciate any help.
❤️ Support the Project
If TaxHacker has helped you save time or manage your finances better, consider supporting its continued development! Your donations help us maintain the project, add new features, and keep it free and open source. Every contribution helps ensure we can keep improving and maintaining this tool for the community.
📄 License
TaxHacker is licensed under the MIT License.
Turn any PDF or image document into structured data for your AI. A powerful, lightweight OCR toolkit that bridges the gap between images/PDFs and LLMs. Supports 100+ languages.

Global Leading OCR Toolkit & Document AI Engine
English | 简体中文 | 繁體中文 | 日本語 | 한국어 | Français | Русский | Español | العربية
![]()
![]()
![]()
![]()
PaddleOCR converts PDF documents and images into structured, LLM-ready data (JSON/Markdown) with industry-leading accuracy. With 70k+ Stars and trusted by top-tier projects like Dify, RAGFlow, and Cherry Studio, PaddleOCR is the bedrock for building intelligent RAG and Agentic applications.
🚀 Key Features
📄 Intelligent Document Parsing (LLM-Ready)
Transforming messy visuals into structured data for the LLM era.
- SOTA Document VLM: Featuring PaddleOCR-VL-1.5 (0.9B), the industry's leading lightweight vision-language model for document parsing. It excels in parsing complex documents across 5 major "Real-World" challenges: Warping, Scanning, Screen Photography, Illumination, and Skewed documents, with structured outputs in Markdown and JSON formats.
- Structure-Aware Conversion: Powered by PP-StructureV3, seamlessly convert complex PDFs and images into Markdown or JSON. Unlike the PaddleOCR-VL series models, it provides more fine-grained coordinate information, including table cell coordinates, text coordinates, and more.
- Production-Ready Efficiency: Achieve commercial-grade accuracy with an ultra-small footprint. Outperforms numerous closed-source solutions in public benchmarks while remaining resource-efficient for edge/cloud deployment.
🔍 Universal Text Recognition (Scene OCR)
The global gold standard for high-speed, multilingual text spotting.
- 100+ Languages Supported: Native recognition for a vast global library. Our PP-OCRv5 single-model solution elegantly handles multilingual mixed documents (Chinese, English, Japanese, Pinyin, etc.).
- Complex Element Mastery: Beyond standard text recognition, we support natural scene text spotting across a wide range of environments, including IDs, street views, books, and industrial components
- Performance Leap: PP-OCRv5 delivers a 13% accuracy boost over previous versions, maintaining the "Extreme Efficiency" that PaddleOCR is famous for.

🛠️ Developer-Centric Ecosystem
- Seamless Integration: The premier choice for the AI Agent ecosystem—deeply integrated with Dify, RAGFlow, Pathway, and Cherry Studio.
- LLM Data Flywheel: A complete pipeline to build high-quality datasets, providing a sustainable "Data Engine" for fine-tuning Large Language Models.
- One-Click Deployment: Supports various hardware backends (NVIDIA GPU, Intel CPU, Kunlunxin XPU, and diverse AI Accelerators).
📣 Recent updates
🔥 [2026.01.29] PaddleOCR v3.4.0 Released: The Era of Irregular Document Parsing
- PaddleOCR-VL-1.5 (SOTA 0.9B VLM): Our latest flagship model for document parsing is now live!
- 94.5% Accuracy on OmniDocBench: Surpassing top-tier general large models and specialized document parsers.
- Real-World Robustness: First to introduce the PP-DocLayoutV3 algorithm for irregular shape positioning, mastering 5 tough scenarios: Skew, Warping, Scanning, Illumination, and Screen Photography.
- Capability Expansion: Now supports Seal Recognition, Text Spotting, and expands to 111 languages (including China’s Tibetan script and Bengali).
- Long Document Mastery: Supports automatic cross-page table merging and hierarchical heading identification.
- Try it now: Available on HuggingFace or our Official Website.
2025.10.16: Release of PaddleOCR 3.3.0
-
Released PaddleOCR-VL:
-
Model Introduction:
- PaddleOCR-VL is a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios. The model has been released on HuggingFace. Everyone is welcome to download and use it! More introduction infomation can be found in PaddleOCR-VL.
-
Core Features:
- Compact yet Powerful VLM Architecture: We present a novel vision-language model that is specifically designed for resource-efficient inference, achieving outstanding performance in element recognition. By integrating a NaViT-style dynamic high-resolution visual encoder with the lightweight ERNIE-4.5-0.3B language model, we significantly enhance the model’s recognition capabilities and decoding efficiency. This integration maintains high accuracy while reducing computational demands, making it well-suited for efficient and practical document processing applications.
- SOTA Performance on Document Parsing: PaddleOCR-VL achieves state-of-the-art performance in both page-level document parsing and element-level recognition. It significantly outperforms existing pipeline-based solutions and exhibiting strong competitiveness against leading vision-language models (VLMs) in document parsing. Moreover, it excels in recognizing complex document elements, such as text, tables, formulas, and charts, making it suitable for a wide range of challenging content types, including handwritten text and historical documents. This makes it highly versatile and suitable for a wide range of document types and scenarios.
- Multilingual Support: PaddleOCR-VL Supports 109 languages, covering major global languages, including but not limited to Chinese, English, Japanese, Latin, and Korean, as well as languages with different scripts and structures, such as Russian (Cyrillic script), Arabic, Hindi (Devanagari script), and Thai. This broad language coverage substantially enhances the applicability of our system to multilingual and globalized document processing scenarios.
-
-
Released PP-OCRv5 Multilingual Recognition Model:
- Improved the accuracy and coverage of Latin script recognition; added support for Cyrillic, Arabic, Devanagari, Telugu, Tamil, and other language systems, covering recognition of 109 languages. The model has only 2M parameters, and the accuracy of some models has increased by over 40% compared to the previous generation.
2025.08.21: Release of PaddleOCR 3.2.0
-
Significant Model Additions:
- Introduced training, inference, and deployment for PP-OCRv5 recognition models in English, Thai, and Greek. The PP-OCRv5 English model delivers an 11% improvement in English scenarios compared to the main PP-OCRv5 model, with the Thai and Greek recognition models achieving accuracies of 82.68% and 89.28%, respectively.
-
Deployment Capability Upgrades:
- Full support for PaddlePaddle framework versions 3.1.0 and 3.1.1.
- Comprehensive upgrade of the PP-OCRv5 C++ local deployment solution, now supporting both Linux and Windows, with feature parity and identical accuracy to the Python implementation.
- High-performance inference now supports CUDA 12, and inference can be performed using either the Paddle Inference or ONNX Runtime backends.
- The high-stability service-oriented deployment solution is now fully open-sourced, allowing users to customize Docker images and SDKs as required.
- The high-stability service-oriented deployment solution also supports invocation via manually constructed HTTP requests, enabling client-side code development in any programming language.
-
Benchmark Support:
- All production lines now support fine-grained benchmarking, enabling measurement of end-to-end inference time as well as per-layer and per-module latency data to assist with performance analysis. Here's how to set up and use the benchmark feature.
- Documentation has been updated to include key metrics for commonly used configurations on mainstream hardware, such as inference latency and memory usage, providing deployment references for users.
-
Bug Fixes:
- Resolved the issue of failed log saving during model training.
- Upgraded the data augmentation component for formula models for compatibility with newer versions of the albumentations dependency, and fixed deadlock warnings when using the tokenizers package in multi-process scenarios.
- Fixed inconsistencies in switch behaviors (e.g.,
use_chart_parsing) in the PP-StructureV3 configuration files compared to other pipelines.
-
Other Enhancements:
- Separated core and optional dependencies. Only minimal core dependencies are required for basic text recognition; additional dependencies for document parsing and information extraction can be installed as needed.
- Enabled support for NVIDIA RTX 50 series graphics cards on Windows; users can refer to the installation guide for the corresponding PaddlePaddle framework versions.
- PP-OCR series models now support returning single-character coordinates.
- Added AIStudio, ModelScope, and other model download sources, allowing users to specify the source for model downloads.
- Added support for chart-to-table conversion via the PP-Chart2Table module.
- Optimized documentation descriptions to improve usability.
🚀 Quick Start
Step 1: Try Online
PaddleOCR official website provides interactive Experience Center and APIs—no setup required, just one click to experience.
Step 2: Local Deployment
For local usage, please refer to the following documentation based on your needs:
- PP-OCR Series: See PP-OCR Documentation
- PaddleOCR-VL Series: See PaddleOCR-VL Documentation
- PP-StructureV3: See PP-StructureV3 Documentation
- More Capabilities: See More Capabilities Documentation
🧩 More Features
- Convert models to ONNX format: Obtaining ONNX Models.
- Accelerate inference using engines like OpenVINO, ONNX Runtime, TensorRT, or perform inference using ONNX format models: High-Performance Inference.
- Accelerate inference using multi-GPU and multi-process: Parallel Inference for Pipelines.
- Integrate PaddleOCR into applications written in C++, C#, Java, etc.: Serving.
🔄 Quick Overview of Execution Results
PP-OCRv5

PP-StructureV3

PaddleOCR-VL

✨ Stay Tuned
⭐ Star this repository to keep up with exciting updates and new releases, including powerful OCR and document parsing capabilities! ⭐

👩👩👧👦 Community
| PaddlePaddle WeChat official account | Join the tech discussion group |
|---|---|
 |
 |
😃 Awesome Projects Leveraging PaddleOCR
PaddleOCR wouldn't be where it is today without its incredible community! 💗 A massive thank you to all our longtime partners, new collaborators, and everyone who's poured their passion into PaddleOCR — whether we've named you or not. Your support fuels our fire!
| Project Name | Description |
|---|---|
Dify  |
Production-ready platform for agentic workflow development. |
RAGFlow  |
RAG engine based on deep document understanding. |
pathway  |
Python ETL framework for stream processing, real-time analytics, LLM pipelines, and RAG. |
MinerU  |
Multi-type Document to Markdown Conversion Tool |
Umi-OCR  |
Free, Open-source, Batch Offline OCR Software. |
cherry-studio  |
A desktop client that supports for multiple LLM providers. |
haystack |
AI orchestration framework to build customizable, production-ready LLM applications. |
OmniParser |
OmniParser: Screen Parsing tool for Pure Vision Based GUI Agent. |
QAnything |
Question and Answer based on Anything. |
| Learn more projects | More projects based on PaddleOCR |
👩👩👧👦 Contributors
🌟 Star
📄 License
This project is released under the Apache 2.0 license.
🎓 Citation
@misc{cui2025paddleocr30technicalreport,
title={PaddleOCR 3.0 Technical Report},
author={Cheng Cui and Ting Sun and Manhui Lin and Tingquan Gao and Yubo Zhang and Jiaxuan Liu and Xueqing Wang and Zelun Zhang and Changda Zhou and Hongen Liu and Yue Zhang and Wenyu Lv and Kui Huang and Yichao Zhang and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2507.05595},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.05595},
}
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}
@misc{cui2026paddleocrvl15multitask09bvlm,
title={PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2026},
eprint={2601.21957},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.21957},
}
ChatDev 2.0: Dev All through LLM-powered Multi-Agent Collaboration
ChatDev 2.0 - DevAll
![]()
A Zero-Code Multi-Agent Platform for Developing Everything
【📚 Developers | 👥 Contributors|⭐️ ChatDev 1.0 (Legacy)】
📖 Overview
ChatDev has evolved from a specialized software development multi-agent system into a comprehensive multi-agent orchestration platform.
- ChatDev 2.0 (DevAll) is a Zero-Code Multi-Agent Platform for "Developing Everything". It empowers users to rapidly build and execute customized multi-agent systems through simple configuration. No coding is required—users can define agents, workflows, and tasks to orchestrate complex scenarios such as data visualization, 3D generation, and deep research.
- ChatDev 1.0 (Legacy) operates as a Virtual Software Company. It utilizes various intelligent agents (e.g., CEO, CTO, Programmer) participating in specialized functional seminars to automate the entire software development life cycle—including designing, coding, testing, and documenting. It serves as the foundational paradigm for communicative agent collaboration.
🎉 News
• Jan 07, 2026: 🚀 We are excited to announce the official release of ChatDev 2.0 (DevAll)! This version introduces a zero-code multi-agent orchestration platform. The classic ChatDev (v1.x) has been moved to the chatdev1.0 branch for maintenance. More details about ChatDev 2.0 can be found on our official post.
Old News
•Sep 24, 2025: 🎉 Our paper Multi-Agent Collaboration via Evolving Orchestration has been accepted to NeurIPS 2025. The implementation is available in the puppeteer branch of this repository.
•May 26, 2025: 🎉 We propose a novel puppeteer-style paradigm for multi-agent collaboration among large language model based agents. By leveraging a learnable central orchestrator optimized with reinforcement learning, our method dynamically activates and sequences agents to construct efficient, context-aware reasoning paths. This approach not only improves reasoning quality but also reduces computational costs, enabling scalable and adaptable multi-agent cooperation in complex tasks.
See our paper in Multi-Agent Collaboration via Evolving Orchestration.
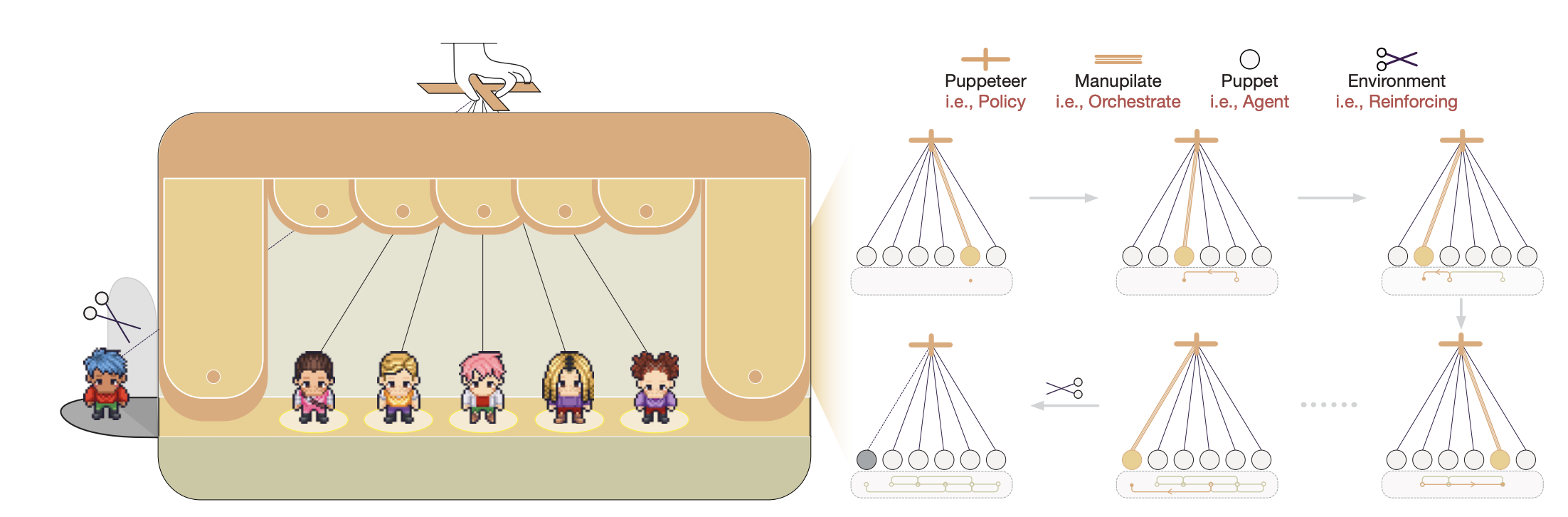
•June 25, 2024: 🎉To foster development in LLM-powered multi-agent collaboration🤖🤖 and related fields, the ChatDev team has curated a collection of seminal papers📄 presented in a open-source interactive e-book📚 format. Now you can explore the latest advancements on the Ebook Website and download the paper list.

•June 12, 2024: We introduced Multi-Agent Collaboration Networks (MacNet) 🎉, which utilize directed acyclic graphs to facilitate effective task-oriented collaboration among agents through linguistic interactions 🤖🤖. MacNet supports co-operation across various topologies and among more than a thousand agents without exceeding context limits. More versatile and scalable, MacNet can be considered as a more advanced version of ChatDev's chain-shaped topology. Our preprint paper is available at https://arxiv.org/abs/2406.07155. This technique has been incorporated into the macnet branch, enhancing support for diverse organizational structures and offering richer solutions beyond software development (e.g., logical reasoning, data analysis, story generation, and more).
• May 07, 2024, we introduced "Iterative Experience Refinement" (IER), a novel method where instructor and assistant agents enhance shortcut-oriented experiences to efficiently adapt to new tasks. This approach encompasses experience acquisition, utilization, propagation and elimination across a series of tasks and making the pricess shorter and efficient. Our preprint paper is available at https://arxiv.org/abs/2405.04219, and this technique will soon be incorporated into ChatDev.
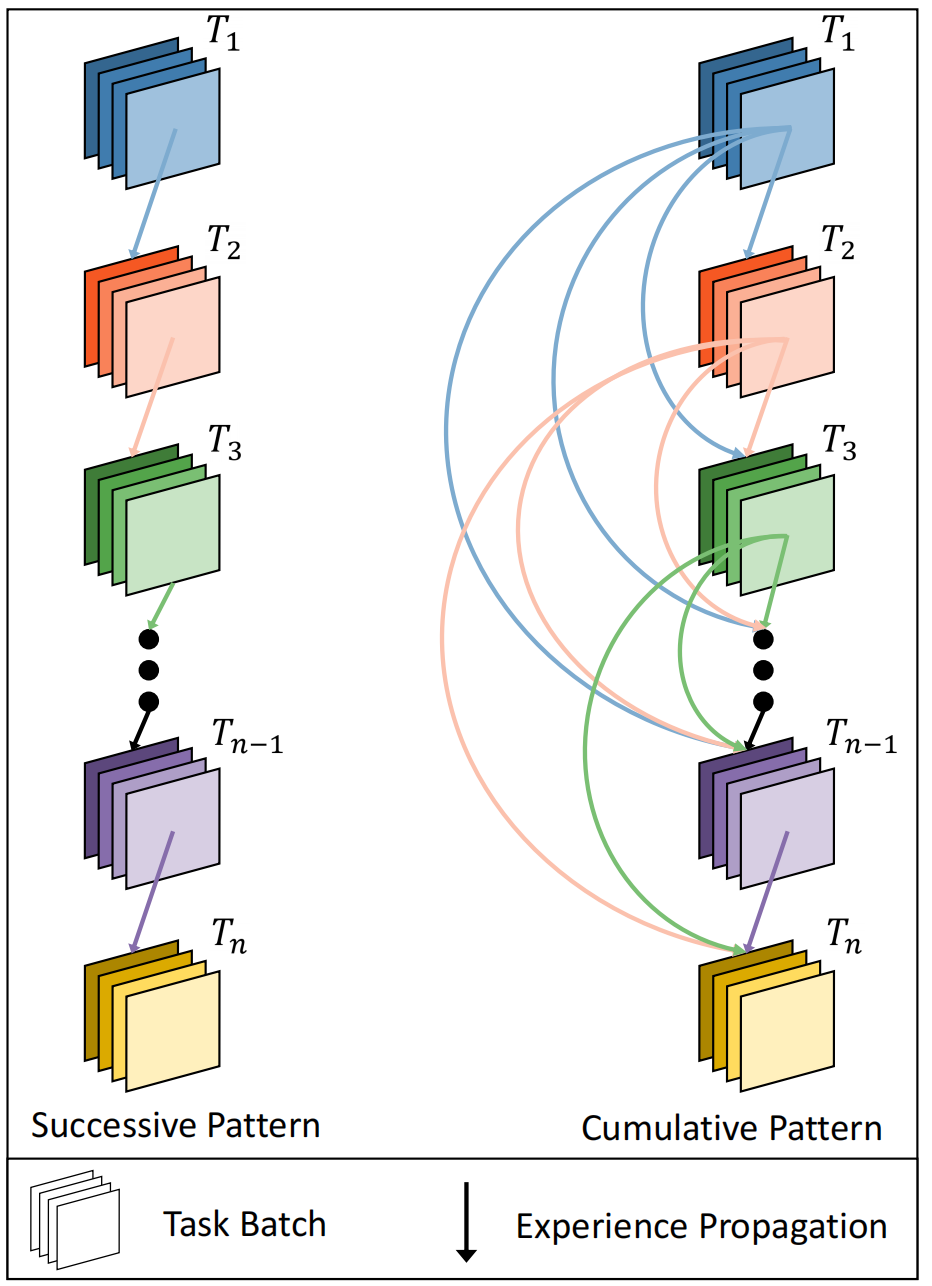
• January 25, 2024: We have integrated Experiential Co-Learning Module into ChatDev. Please see the Experiential Co-Learning Guide.
• December 28, 2023: We present Experiential Co-Learning, an innovative approach where instructor and assistant agents accumulate shortcut-oriented experiences to effectively solve new tasks, reducing repetitive errors and enhancing efficiency. Check out our preprint paper at https://arxiv.org/abs/2312.17025 and this technique will soon be integrated into ChatDev.
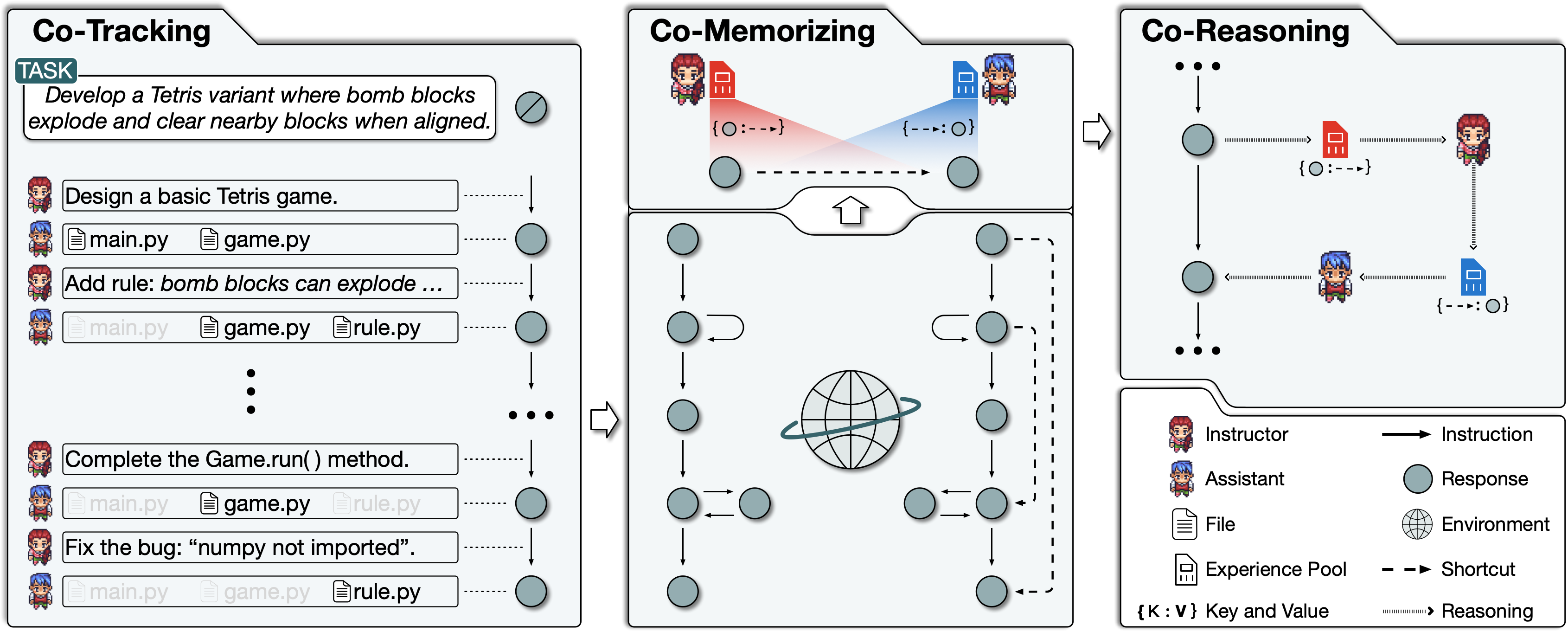

• November 2, 2023: ChatDev is now supported with a new feature: incremental development, which allows agents to develop upon existing codes. Try --config "incremental" --path "[source_code_directory_path]" to start it.

• October 26, 2023: ChatDev is now supported with Docker for safe execution (thanks to contribution from ManindraDeMel). Please see Docker Start Guide.

• September 25, 2023: The Git mode is now available, enabling the programmer ![]() to utilize Git for version control. To enable this feature, simply set
to utilize Git for version control. To enable this feature, simply set "git_management" to "True" in ChatChainConfig.json. See guide.
• September 20, 2023: The Human-Agent-Interaction mode is now available! You can get involved with the ChatDev team by playing the role of reviewer ![]() and making suggestions to the programmer
and making suggestions to the programmer ![]() ;
;
try python3 run.py --task [description_of_your_idea] --config "Human". See guide and example.

• September 1, 2023: The Art mode is available now! You can activate the designer agent ![]() to generate images used in the software;
to generate images used in the software;
try python3 run.py --task [description_of_your_idea] --config "Art". See guide and example.
• August 28, 2023: The system is publicly available.
• August 17, 2023: The v1.0.0 version was ready for release.
• July 30, 2023: Users can customize ChatChain, Phasea and Role settings. Additionally, both online Log mode and replay
mode are now supported.
• July 16, 2023: The preprint paper associated with this project was published.
• June 30, 2023: The initial version of the ChatDev repository was released.
🚀 Quick Start
📋 Prerequisites
- OS: macOS / Linux / WSL / Windows
- Python: 3.12+
- Node.js: 18+
- Package Manager: uv
📦 Installation
-
Backend Dependencies (Python managed by
uv):uv sync -
Frontend Dependencies (Vite + Vue 3):
cd frontend && npm install
🔑 Configuration
- Environment Variables:
cp .env.example .env - Model Keys: Set
API_KEYandBASE_URLin.envfor your LLM provider. - YAML placeholders: Use
${VAR}(e.g.,${API_KEY})in configuration files to reference these variables.
⚡️ Run the Application
Using Makefile (Recommended)
Start both Backend and Frontent:
make dev
Then access the Web Console at http://localhost:5173.
Manual Commands
-
Start Backend:
# Run from the project root uv run python server_main.py --port 6400 --reloadRemove
--reloadif output files (e.g., GameDev) trigger restarts, which interrupts tasks and loses progress. -
Start Frontend:
cd frontend VITE_API_BASE_URL=http://localhost:6400 npm run devThen access the Web Console at http://localhost:5173.
💡 Tip: If the frontend fails to connect to the backend, the default port
6400may already be occupied.
Please switch both services to an available port, for example:- Backend: start with
--port 6401 - Frontend: set
VITE_API_BASE_URL=http://localhost:6401
- Backend: start with
Utility Commands
-
Help command:
make help -
Sync YAML workflows to frontend:
make syncUploads all workflow files from
yaml_instance/to the database. -
Validate all YAML workflows:
make validate-yamlsChecks all YAML files for syntax and schema errors.
🦞 Run with OpenClaw
OpenClaw can integrate with ChatDev by invoking existing agent teams or dynamically creating new agent teams within ChatDev.
To get started:
-
Start the ChatDev 2.0 backend.
-
Install the required skills for your OpenClaw instance:
clawdhub install chatdev -
Ask your OpenClaw to create a ChatDev workflow. For example:
-
Automated information collection and content publishing
Create a ChatDev workflow to automatically collect trending information, generate a Xiaohongshu post, and publish it. -
Multi-agent geopolitical simulation
Create a ChatDev workflow with multiple agents to simulate possible future developments of the Middle East situation.
🐳 Run with Docker
Alternatively, you can run the entire application using Docker Compose. This method simplifies dependency management and provides a consistent environment.
-
Prerequisites:
- Docker and Docker Compose installed.
- Ensure you have a
.envfile in the project root for your API keys.
-
Build and Run:
# From the project root docker compose up --build -
Access:
- Backend:
http://localhost:6400 - Frontend:
http://localhost:5173
- Backend:
The services will automatically restart if they crash, and local file changes will be reflected inside the containers for live development.
💡 How to Use
🖥️ Web Console
The DevAll interface provides a seamless experience for both construction and execution
-
Tutorial: Comprehensive step-by-step guides and documentation integrated directly into the platform to help you get started quickly.
-
Workflow: A visual canvas to design your multi-agent systems. Configure node parameters, define context flows, and orchestrate complex agent interactions with drag-and-drop ease.
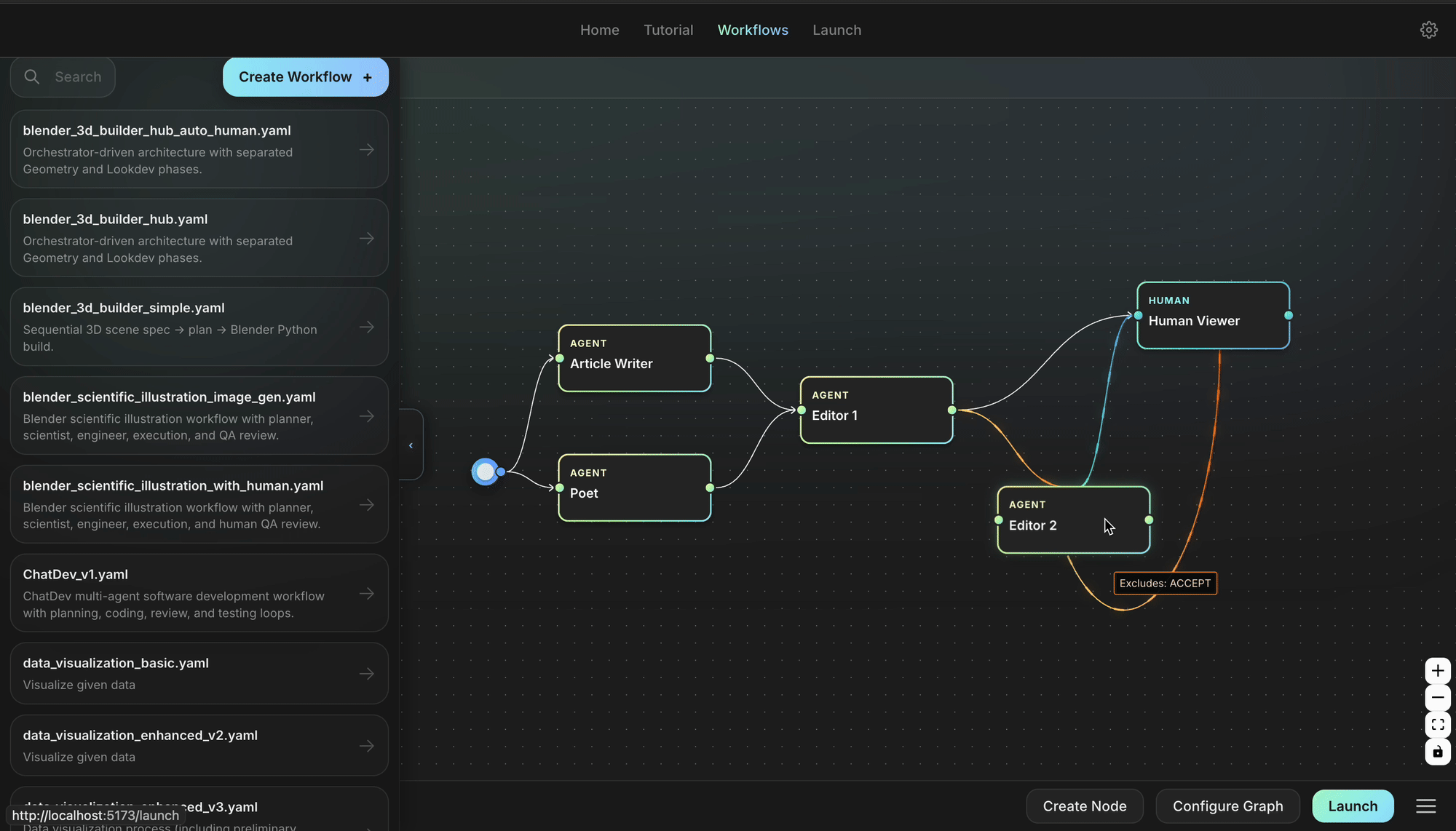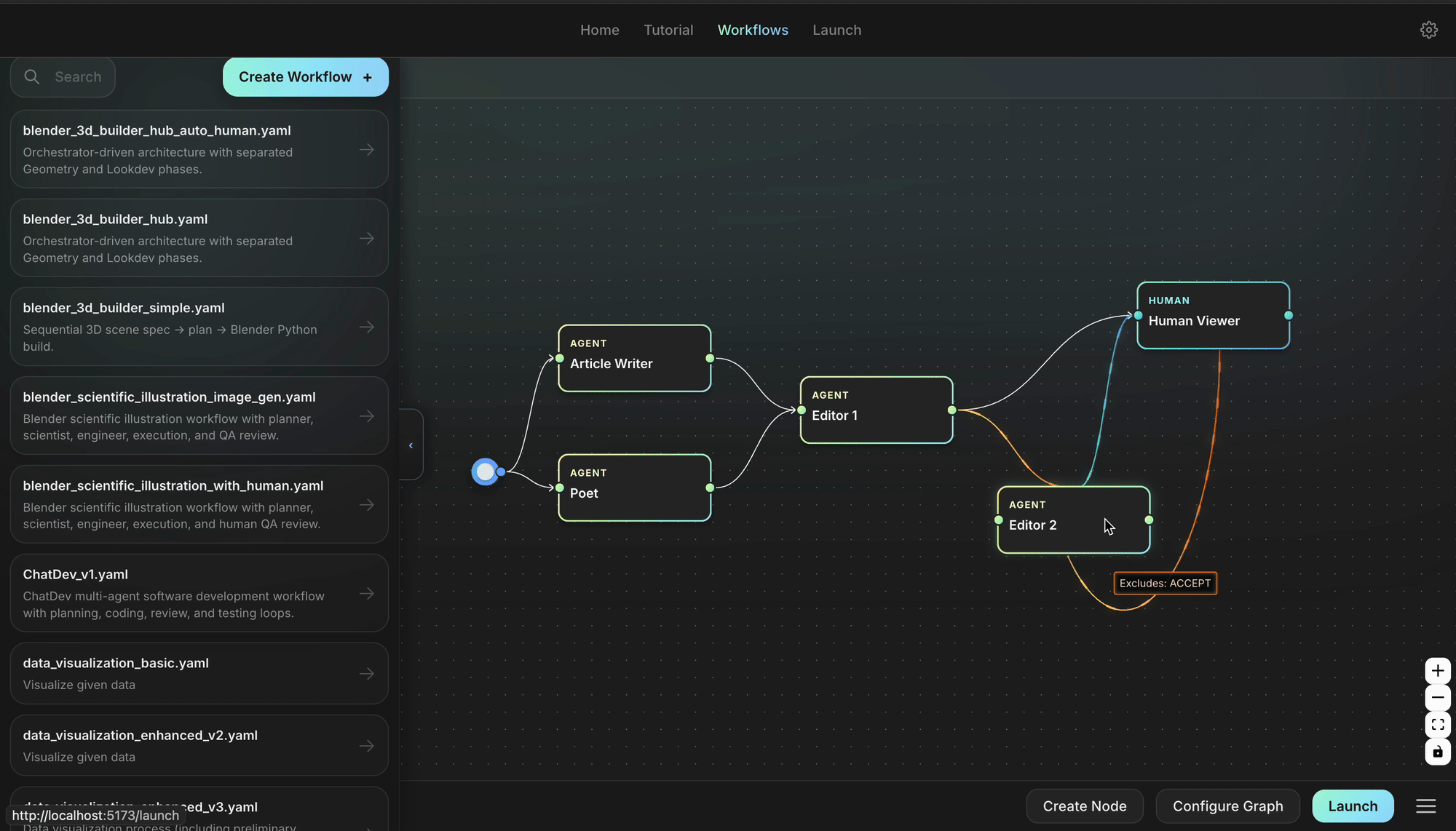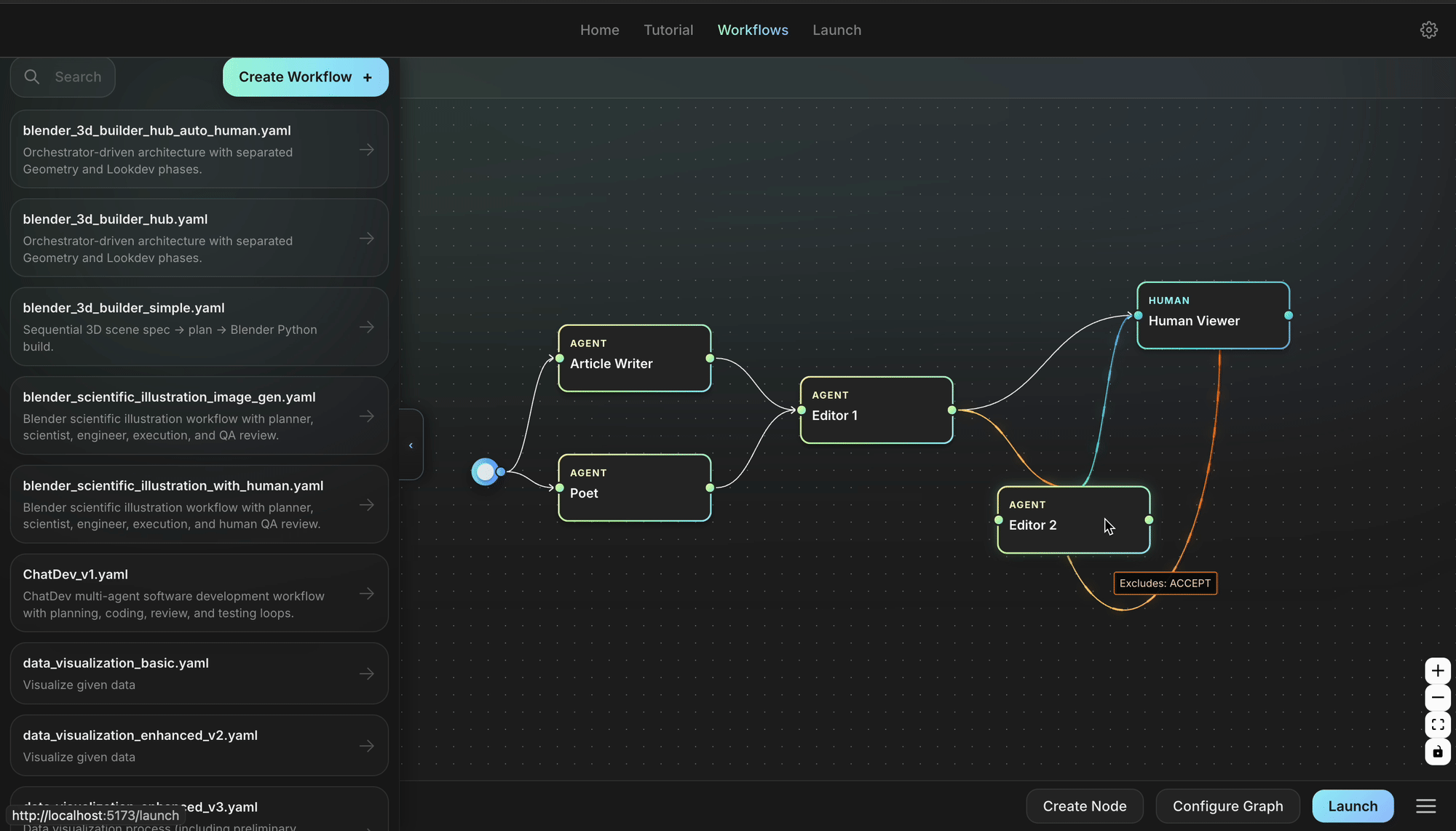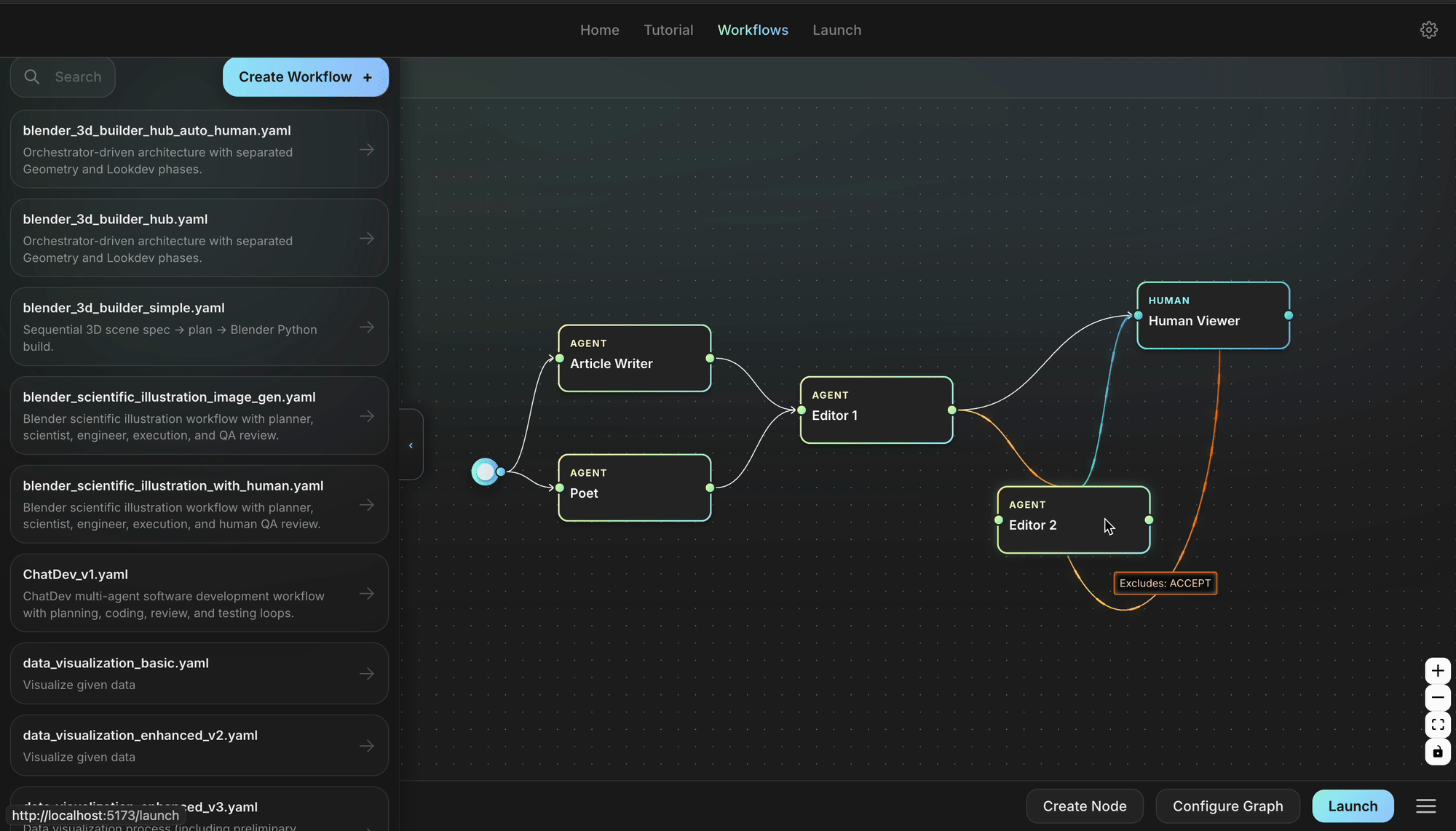
-
Launch: Initiate workflows, monitor real-time logs, inspect intermediate artifacts, and provide human-in-the-loop feedback.
🧰 Python SDK
For automation and batch processing, use our lightweight Python SDK to execute workflows programmatically and retrieve results directly.
from runtime.sdk import run_workflow
# Execute a workflow and get the final node message
result = run_workflow(
yaml_file="yaml_instance/demo.yaml",
task_prompt="Summarize the attached document in one sentence.",
attachments=["/path/to/document.pdf"],
variables={"API_KEY": "sk-xxxx"} # Override .env variables if needed
)
if result.final_message:
print(f"Output: {result.final_message.text_content()}")
We have released the ChatDev Python SDK (PyPI package chatdev), so you can also run YAML workflow and multi-agent tasks directly in Python. For installation and version details, see PyPI: chatdev 0.1.0.
⚙️ For Developers
For secondary development and extensions, please proceed with this section.
Extend DevAll with new nodes, providers, and tools.
The project is organized into a modular structure:
- Core Systems:
server/hosts the FastAPI backend, whileruntime/manages agent abstraction and tool execution. - Orchestration:
workflow/handles the multi-agent logic, driven by configurations inentity/. - Frontend:
frontend/contains the Vue 3 Web Console. - Extensibility:
functions/is the place for custom Python tools.
Relevant reference documentation:
- Getting Started: Start Guide
- Core Modules: Workflow Authoring, Memory, and Tooling
🌟 Featured Workflows
We provide robust, out-of-the-box templates for common scenarios. All runnable workflow configs are located in yaml_instance/.
- Demos: Files named
demo_*.yamlshowcase specific features or modules. - Implementations: Files named directly (e.g.,
ChatDev_v1.yaml) are full in-house or recreated workflows. As follows:
📋 Workflow Collection
| Category | Workflow | Case |
|---|---|---|
| 📈 Data Visualization | data_visualization_basic.yamldata_visualization_enhanced.yaml |
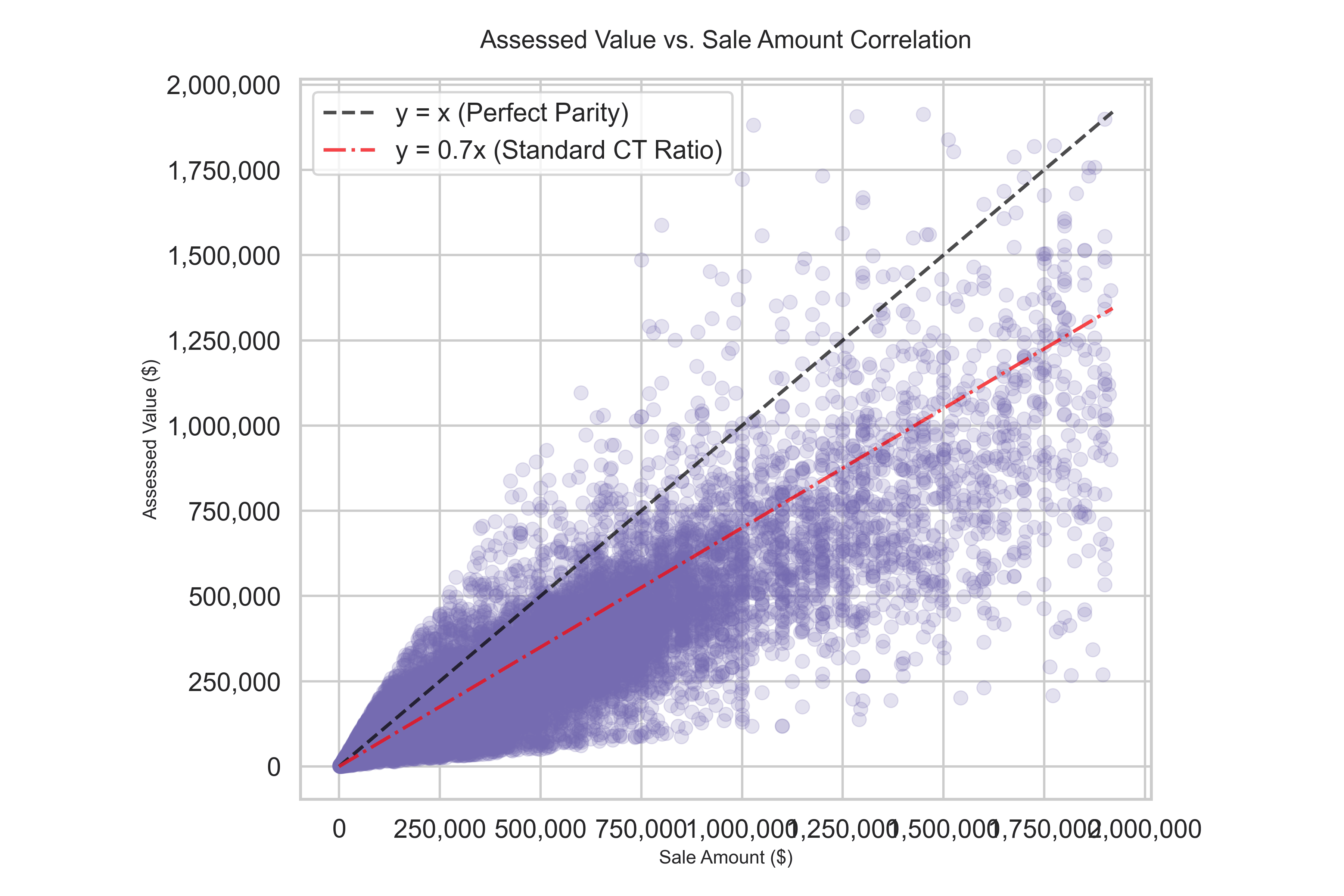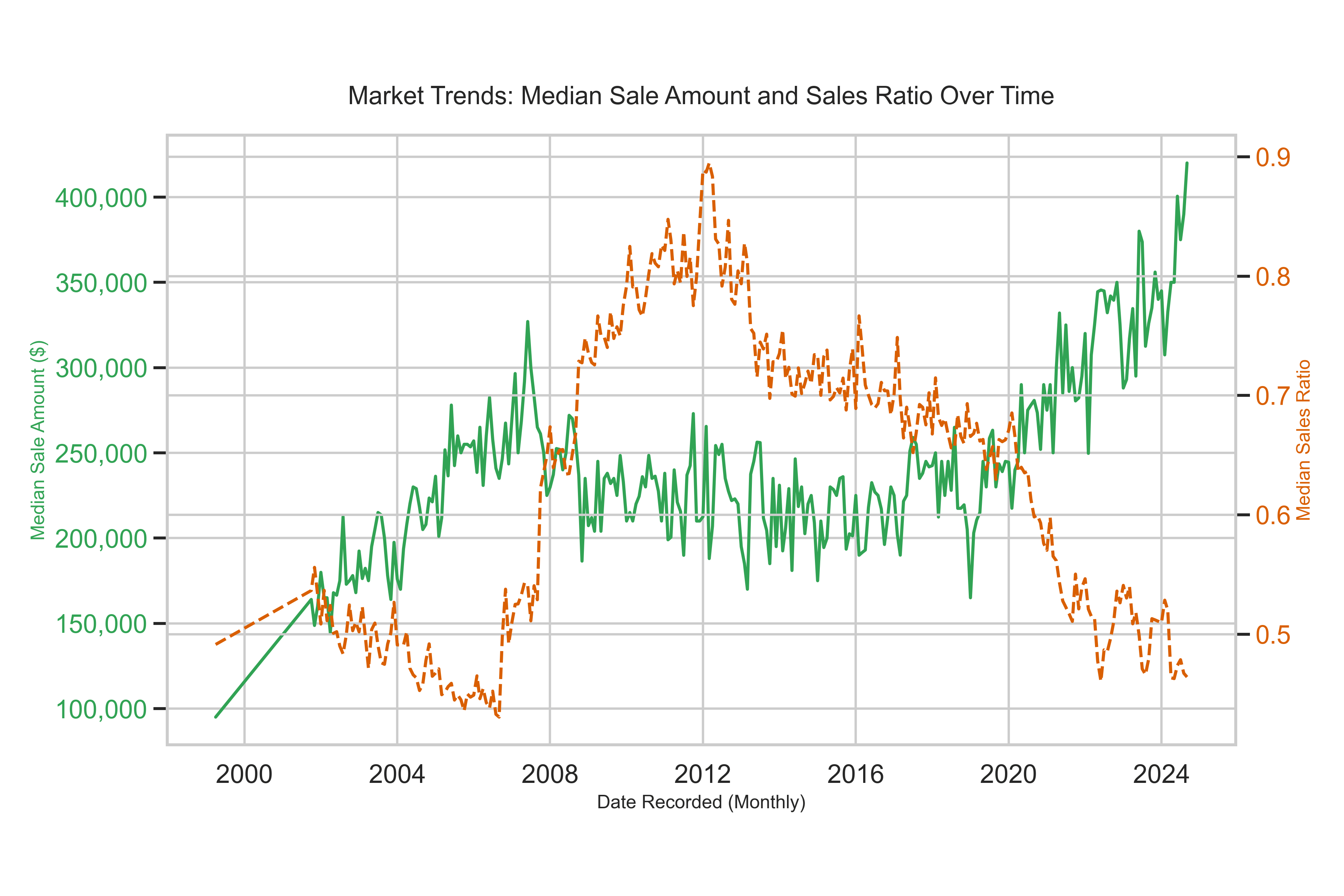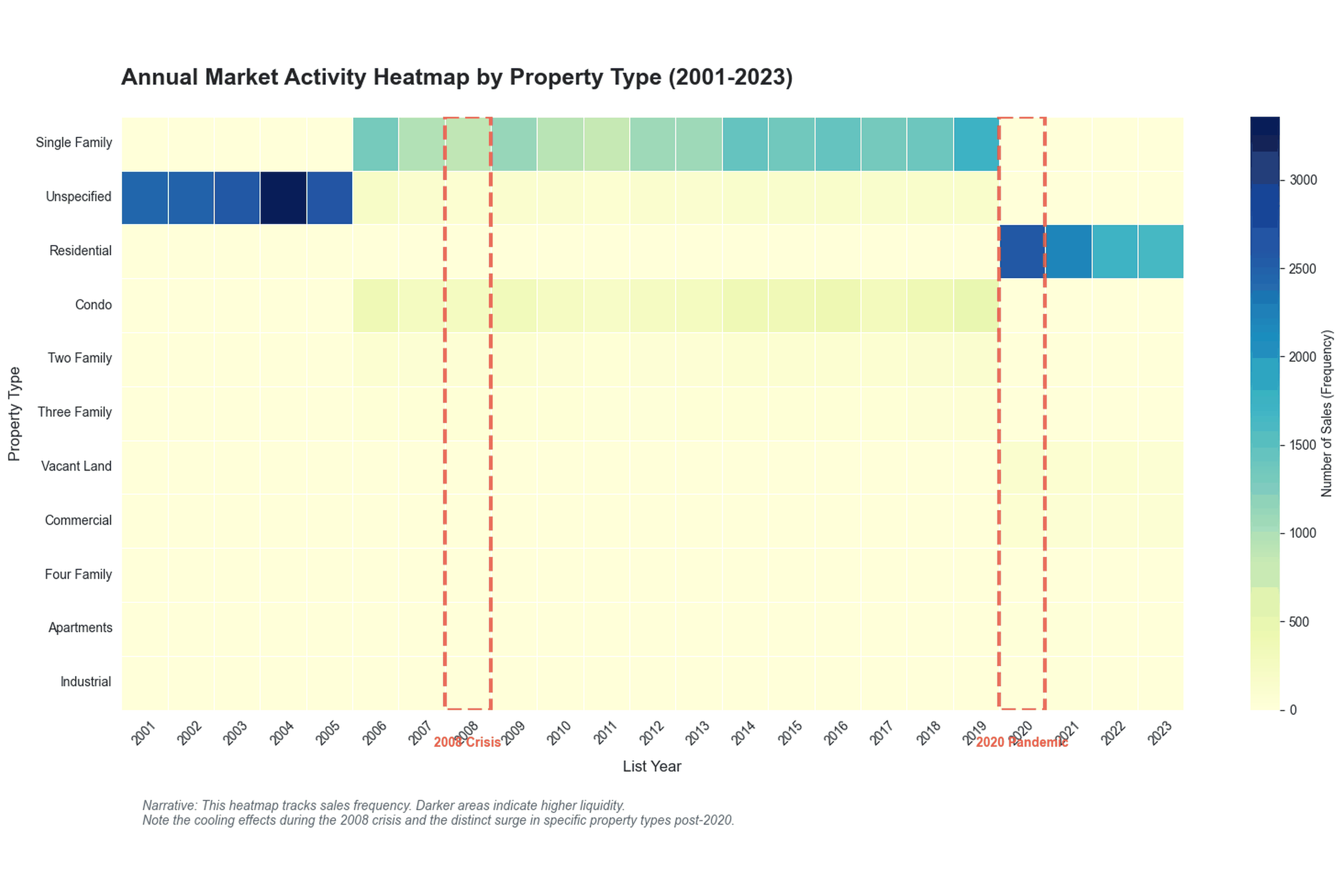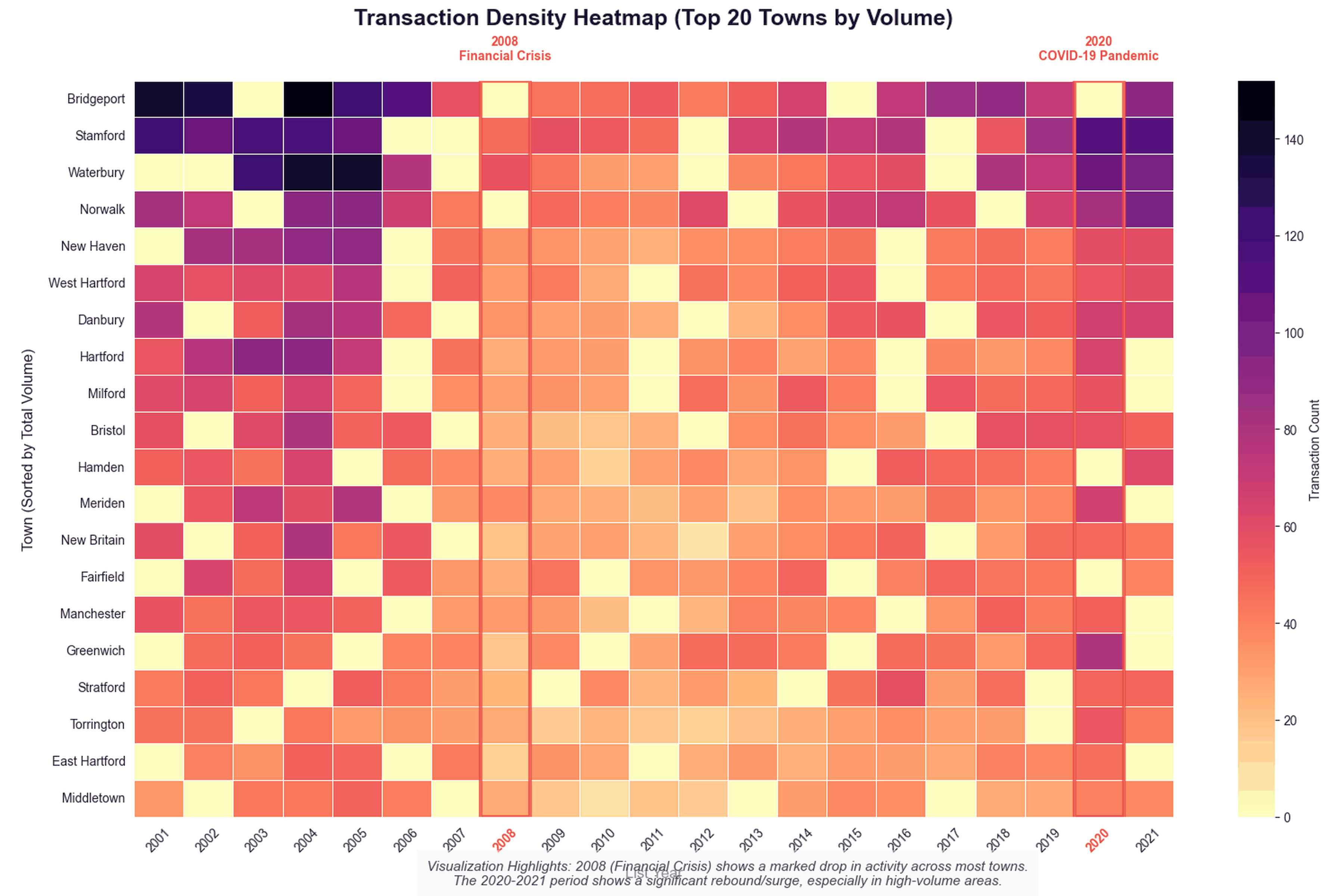 Prompt: "Create 4–6 high-quality PNG charts for my large real-estate transactions dataset." |
| 🛠️ 3D Generation (Requires Blender & blender-mcp) |
blender_3d_builder_simple.yamlblender_3d_builder_hub.yamlblender_scientific_illustration.yaml |
 Prompt: "Please build a Christmas tree." |
| 🎮 Game Dev | GameDev_v1.yamlChatDev_v1.yaml |
 Prompt: "Please help me design and develop a Tank Battle game." |
| 📚 Deep Research | deep_research_v1.yaml |
 Prompt: "Research about recent advances in the field of LLM-based agent RL" |
| 🎓 Teach Video | teach_video.yaml (Please run command uv add manim before running this workflow) |
 Prompt: "讲一下什么是凸优化" |
💡 Usage Guide
For those implementations, you can use the Launch tab to execute them.
- Select: Choose a workflow in the Launch tab.
- Upload: Upload necessary files (e.g.,
.csvfor data analysis) if required. - Prompt: Enter your request (e.g., "Visualize the sales trends" or "Design a snake game").
🤝 Contributing
We welcome contributions from the community! Whether you're fixing bugs, adding new workflow templates, or sharing high-quality cases/artifacts produced by DevAll, your help is much appreciated. Feel free to contribute by submitting Issues or Pull Requests.
By contributing to DevAll, you'll be recognized in our Contributors list below. Check out our Developer Guide to get started!
👥 Contributors
Primary Contributors
 NA-Wen |
 zxrys |
 swugi |
 huatl98 |
Contributors
 LaansDole |
 zivkovicp |
 shiowen |
 kilo2127 |
 AckerlyLau |
 rainoeelmae |
 conprour |
 Br1an67 |
 NINE-J |
 Yanghuabei |
🤝 Acknowledgments







🔎 Citation
@article{chatdev,
title = {ChatDev: Communicative Agents for Software Development},
author = {Chen Qian and Wei Liu and Hongzhang Liu and Nuo Chen and Yufan Dang and Jiahao Li and Cheng Yang and Weize Chen and Yusheng Su and Xin Cong and Juyuan Xu and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal = {arXiv preprint arXiv:2307.07924},
url = {https://arxiv.org/abs/2307.07924},
year = {2023}
}
@article{colearning,
title = {Experiential Co-Learning of Software-Developing Agents},
author = {Chen Qian and Yufan Dang and Jiahao Li and Wei Liu and Zihao Xie and Yifei Wang and Weize Chen and Cheng Yang and Xin Cong and Xiaoyin Che and Zhiyuan Liu and Maosong Sun},
journal = {arXiv preprint arXiv:2312.17025},
url = {https://arxiv.org/abs/2312.17025},
year = {2023}
}
@article{macnet,
title={Scaling Large-Language-Model-based Multi-Agent Collaboration},
author={Chen Qian and Zihao Xie and Yifei Wang and Wei Liu and Yufan Dang and Zhuoyun Du and Weize Chen and Cheng Yang and Zhiyuan Liu and Maosong Sun}
journal={arXiv preprint arXiv:2406.07155},
url = {https://arxiv.org/abs/2406.07155},
year={2024}
}
@article{iagents,
title={Autonomous Agents for Collaborative Task under Information Asymmetry},
author={Wei Liu and Chenxi Wang and Yifei Wang and Zihao Xie and Rennai Qiu and Yufan Dnag and Zhuoyun Du and Weize Chen and Cheng Yang and Chen Qian},
journal={arXiv preprint arXiv:2406.14928},
url = {https://arxiv.org/abs/2406.14928},
year={2024}
}
@article{puppeteer,
title={Multi-Agent Collaboration via Evolving Orchestration},
author={Yufan Dang and Chen Qian and Xueheng Luo and Jingru Fan and Zihao Xie and Ruijie Shi and Weize Chen and Cheng Yang and Xiaoyin Che and Ye Tian and Xuantang Xiong and Lei Han and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2505.19591},
url={https://arxiv.org/abs/2505.19591},
year={2025}
}
📬 Contact
If you have any questions, feedback, or would like to get in touch, please feel free to reach out to us via email at qianc62@gmail.com